 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Persistence of Cultural Memory: Investigating Multimodal Iconicity in Diffusion Models
Nov 14, 2025Our work addresses the ambiguity between generalization and memorization in text-to-image diffusion models, focusing on a specific case we term multimodal iconicity. This refers to instances where images and texts evoke culturally shared associations, such as when a title recalls a familiar artwork or film scene. While prior research on memorization and unlearning emphasizes forgetting, we examine what is remembered and how, focusing on the balance between recognizing cultural references and reproducing them. We introduce an evaluation framework that separates recognition, whether a model identifies a reference, from realization, how it depicts it through replication or reinterpretation, quantified through measures capturing both dimensions. By evaluating five diffusion models across 767 Wikidata-derived cultural references spanning static and dynamic imagery, we show that our framework distinguishes replication from transformation more effectively than existing similarity-based methods. To assess linguistic sensitivity, we conduct prompt perturbation experiments using synonym substitutions and literal image descriptions, finding that models often reproduce iconic visual structures even when textual cues are altered. Finally, our analysis shows that cultural alignment correlates not only with training data frequency, but also textual uniqueness, reference popularity, and creation date. Our work reveals that the value of diffusion models lies not only in what they reproduce but in how they transform and recontextualize cultural knowledge, advancing evaluation beyond simple text-image matching toward richer contextual understanding.
Exploring Language Patterns of Prompts in Text-to-Image Generation and Their Impact on Visual Diversity
Apr 19, 2025Following the initial excitement, Text-to-Image (TTI) models are now being examined more critically. While much of the discourse has focused on biases and stereotypes embedded in large-scale training datasets, the sociotechnical dynamics of user interactions with these models remain underexplored. This study examines the linguistic and semantic choices users make when crafting prompts and how these choices influence the diversity of generated outputs. Analyzing over six million prompts from the Civiverse dataset on the CivitAI platform across seven months, we categorize users into three groups based on their levels of linguistic experimentation: consistent repeaters, occasional repeaters, and non-repeaters. Our findings reveal that as user participation grows over time, prompt language becomes increasingly homogenized through the adoption of popular community tags and descriptors, with repeated prompts comprising 40-50% of submissions. At the same time, semantic similarity and topic preferences remain relatively stable, emphasizing common subjects and surface aesthetics. Using Vendi scores to quantify visual diversity, we demonstrate a clear correlation between lexical similarity in prompts and the visual similarity of generated images, showing that linguistic repetition reinforces less diverse representations. These findings highlight the significant role of user-driven factors in shaping AI-generated imagery, beyond inherent model biases, and underscore the need for tools and practices that encourage greater linguistic and thematic experimentation within TTI systems to foster more inclusive and diverse AI-generated content.
The Myth of Culturally Agnostic AI Models
Nov 29, 2022

The paper discusses the potential of large vision-language models as objects of interest for empirical cultural studies. Focusing on the comparative analysis of outputs from two popular text-to-image synthesis models, DALL-E 2 and Stable Diffusion, the paper tries to tackle the pros and cons of striving towards culturally agnostic vs. culturally specific AI models. The paper discusses several examples of memorization and bias in generated outputs which showcase the trade-off between risk mitigation and cultural specificity, as well as the overall impossibility of developing culturally agnostic models.
Understanding and Creating Art with AI: Review and Outlook
Feb 18, 2021
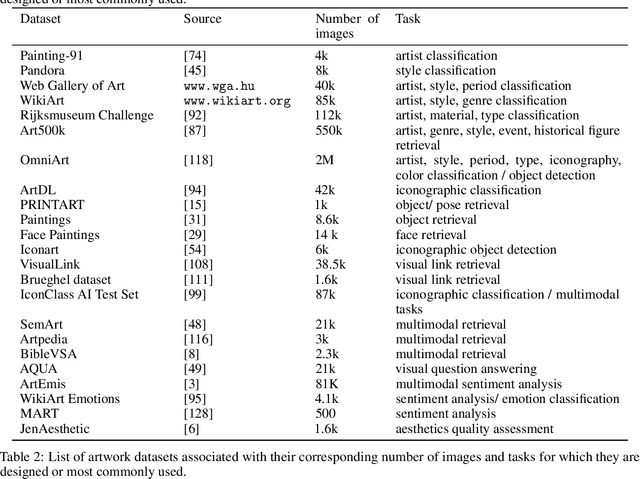
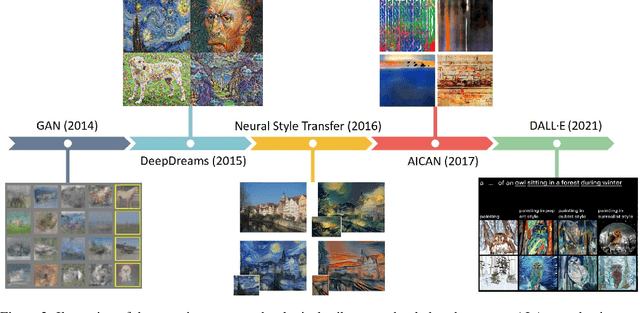

Technologies related to artificial intelligence (AI) have a strong impact on the changes of research and creative practices in visual arts. The growing number of research initiatives and creative applications that emerge in the intersection of AI and art, motivates us to examine and discuss the creative and explorative potentials of AI technologies in the context of art. This paper provides an integrated review of two facets of AI and art: 1) AI is used for art analysis and employed on digitized artwork collections; 2) AI is used for creative purposes and generating novel artworks. In the context of AI-related research for art understanding, we present a comprehensive overview of artwork datasets and recent works that address a variety of tasks such as classification, object detection, similarity retrieval, multimodal representations, computational aesthetics, etc. In relation to the role of AI in creating art, we address various practical and theoretical aspects of AI Art and consolidate related works that deal with those topics in detail. Finally, we provide a concise outlook on the future progression and potential impact of AI technologies on our understanding and creation of art.
Iconographic Image Captioning for Artworks
Feb 07, 2021
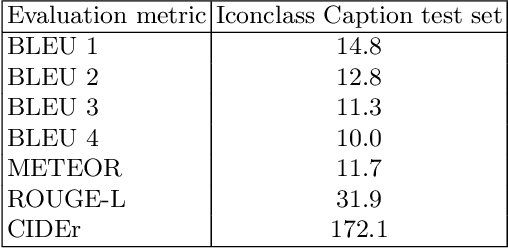


Image captioning implies automatically generating textual descriptions of images based only on the visual input. Although this has been an extensively addressed research topic in recent years, not many contributions have been made in the domain of art historical data. In this particular context, the task of image captioning is confronted with various challenges such as the lack of large-scale datasets of image-text pairs, the complexity of meaning associated with describing artworks and the need for expert-level annotations. This work aims to address some of those challenges by utilizing a novel large-scale dataset of artwork images annotated with concepts from the Iconclass classification system designed for art and iconography. The annotations are processed into clean textual description to create a dataset suitable for training a deep neural network model on the image captioning task. Motivated by the state-of-the-art results achieved in generating captions for natural images, a transformer-based vision-language pre-trained model is fine-tuned using the artwork image dataset. Quantitative evaluation of the results is performed using standard image captioning metrics. The quality of the generated captions and the model's capacity to generalize to new data is explored by employing the model on a new collection of paintings and performing an analysis of the relation between commonly generated captions and the artistic genre. The overall results suggest that the model can generate meaningful captions that exhibit a stronger relevance to the art historical context, particularly in comparison to captions obtained from models trained only on natural image datasets.