 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIconographic Image Captioning for Artworks
Paper and Code
Feb 07, 2021
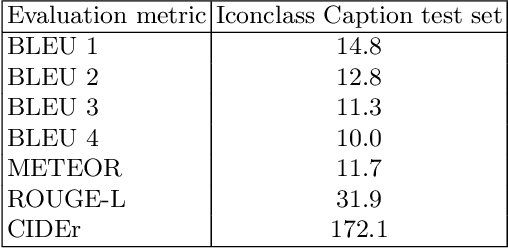


Image captioning implies automatically generating textual descriptions of images based only on the visual input. Although this has been an extensively addressed research topic in recent years, not many contributions have been made in the domain of art historical data. In this particular context, the task of image captioning is confronted with various challenges such as the lack of large-scale datasets of image-text pairs, the complexity of meaning associated with describing artworks and the need for expert-level annotations. This work aims to address some of those challenges by utilizing a novel large-scale dataset of artwork images annotated with concepts from the Iconclass classification system designed for art and iconography. The annotations are processed into clean textual description to create a dataset suitable for training a deep neural network model on the image captioning task. Motivated by the state-of-the-art results achieved in generating captions for natural images, a transformer-based vision-language pre-trained model is fine-tuned using the artwork image dataset. Quantitative evaluation of the results is performed using standard image captioning metrics. The quality of the generated captions and the model's capacity to generalize to new data is explored by employing the model on a new collection of paintings and performing an analysis of the relation between commonly generated captions and the artistic genre. The overall results suggest that the model can generate meaningful captions that exhibit a stronger relevance to the art historical context, particularly in comparison to captions obtained from models trained only on natural image datasets.