 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding surface codes with deep reinforcement learning and probabilistic policy reuse
Dec 22, 2022Quantum computing (QC) promises significant advantages on certain hard computational tasks over classical computers. However, current quantum hardware, also known as noisy intermediate-scale quantum computers (NISQ), are still unable to carry out computations faithfully mainly because of the lack of quantum error correction (QEC) capability. A significant amount of theoretical studies have provided various types of QEC codes; one of the notable topological codes is the surface code, and its features, such as the requirement of only nearest-neighboring two-qubit control gates and a large error threshold, make it a leading candidate for scalable quantum computation. Recent developments of machine learning (ML)-based techniques especially the reinforcement learning (RL) methods have been applied to the decoding problem and have already made certain progress. Nevertheless, the device noise pattern may change over time, making trained decoder models ineffective. In this paper, we propose a continual reinforcement learning method to address these decoding challenges. Specifically, we implement double deep Q-learning with probabilistic policy reuse (DDQN-PPR) model to learn surface code decoding strategies for quantum environments with varying noise patterns. Through numerical simulations, we show that the proposed DDQN-PPR model can significantly reduce the computational complexity. Moreover, increasing the number of trained policies can further improve the agent's performance. Our results open a way to build more capable RL agents which can leverage previously gained knowledge to tackle QEC challenges.
Quantum Architecture Search via Continual Reinforcement Learning
Dec 10, 2021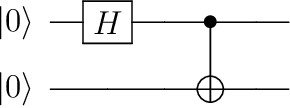

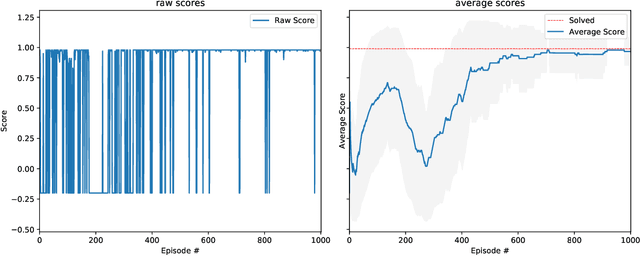

Quantum computing has promised significant improvement in solving difficult computational tasks over classical computers. Designing quantum circuits for practical use, however, is not a trivial objective and requires expert-level knowledge. To aid this endeavor, this paper proposes a machine learning-based method to construct quantum circuit architectures. Previous works have demonstrated that classical deep reinforcement learning (DRL) algorithms can successfully construct quantum circuit architectures without encoded physics knowledge. However, these DRL-based works are not generalizable to settings with changing device noises, thus requiring considerable amounts of training resources to keep the RL models up-to-date. With this in mind, we incorporated continual learning to enhance the performance of our algorithm. In this paper, we present the Probabilistic Policy Reuse with deep Q-learning (PPR-DQL) framework to tackle this circuit design challenge. By conducting numerical simulations over various noise patterns, we demonstrate that the RL agent with PPR was able to find the quantum gate sequence to generate the two-qubit Bell state faster than the agent that was trained from scratch. The proposed framework is general and can be applied to other quantum gate synthesis or control problems -- including the automatic calibration of quantum devices.