 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Topic modeling in Twitter through Community Pooling
Dec 20, 2021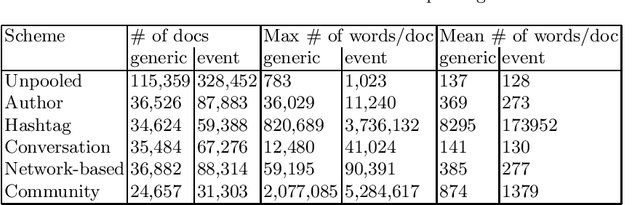
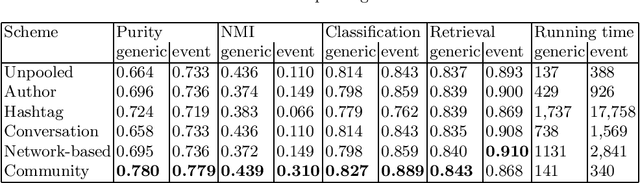
Social networks play a fundamental role in propagation of information and news. Characterizing the content of the messages becomes vital for different tasks, like breaking news detection, personalized message recommendation, fake users detection, information flow characterization and others. However, Twitter posts are short and often less coherent than other text documents, which makes it challenging to apply text mining algorithms to these datasets efficiently. Tweet-pooling (aggregating tweets into longer documents) has been shown to improve automatic topic decomposition, but the performance achieved in this task varies depending on the pooling method. In this paper, we propose a new pooling scheme for topic modeling in Twitter, which groups tweets whose authors belong to the same community (group of users who mainly interact with each other but not with other groups) on a user interaction graph. We present a complete evaluation of this methodology, state of the art schemes and previous pooling models in terms of the cluster quality, document retrieval tasks performance and supervised machine learning classification score. Results show that our Community polling method outperformed other methods on the majority of metrics in two heterogeneous datasets, while also reducing the running time. This is useful when dealing with big amounts of noisy and short user-generated social media texts. Overall, our findings contribute to an improved methodology for identifying the latent topics in a Twitter dataset, without the need of modifying the basic machinery of a topic decomposition model.
Predicting Shifting Individuals Using Text Mining and Graph Machine Learning on Twitter
Aug 24, 2020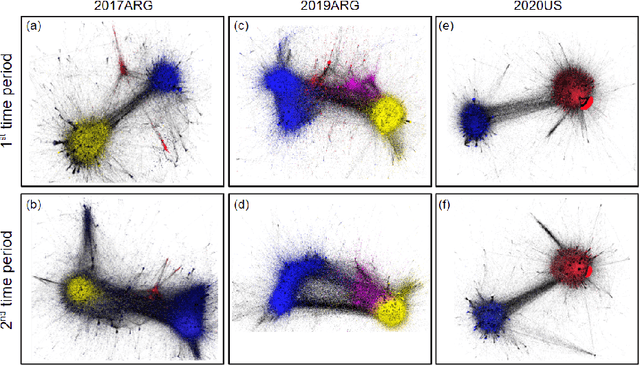
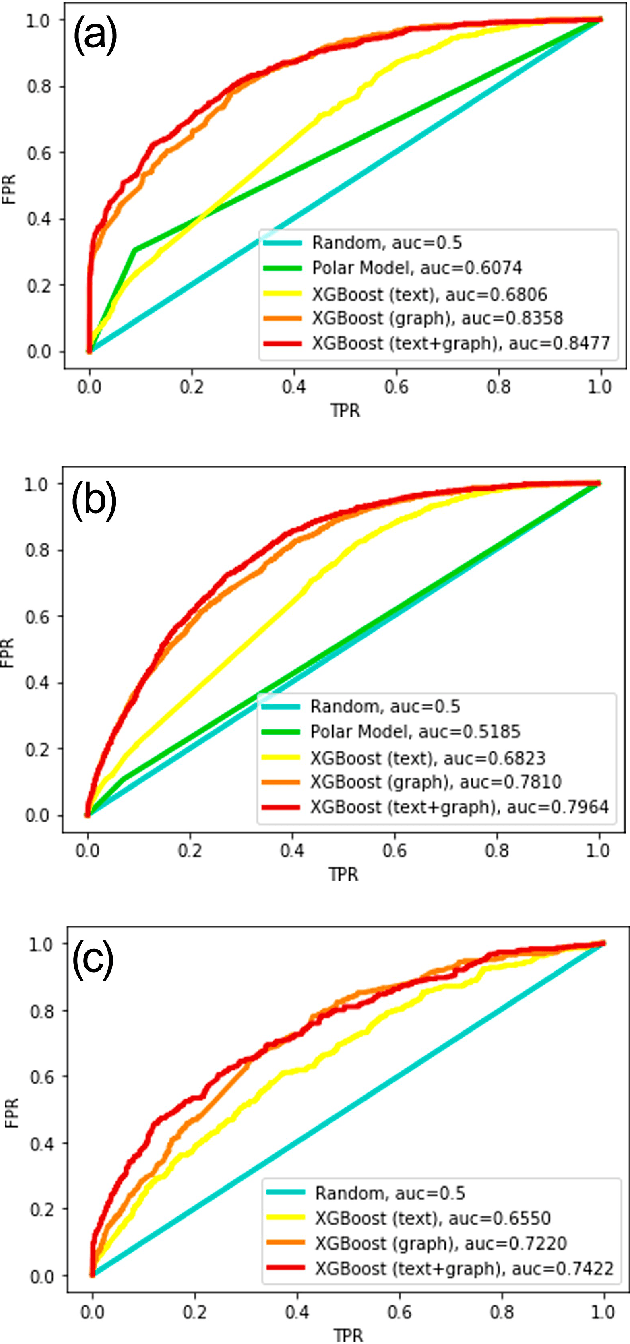
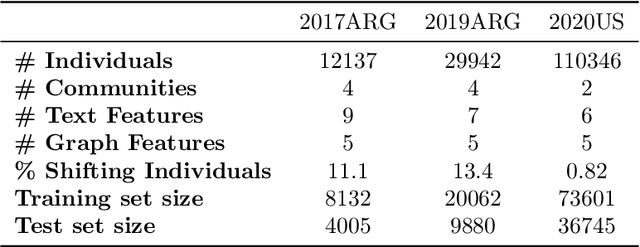
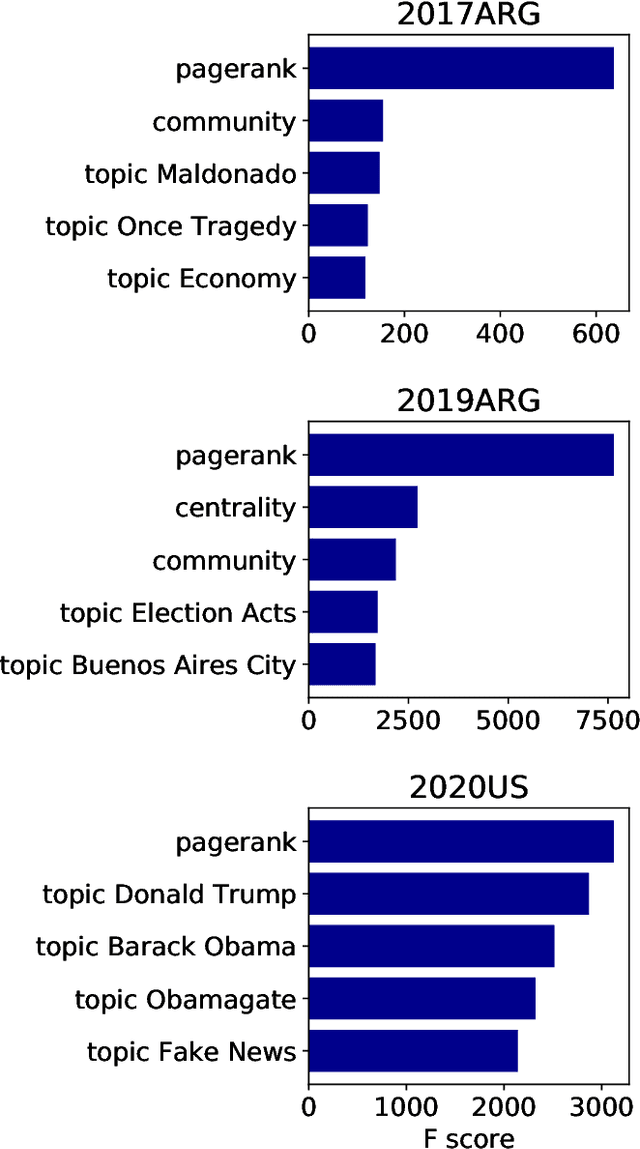
The formation of majorities in public discussions often depends on individuals who shift their opinion over time. The detection and characterization of these type of individuals is therefore extremely important for political analysis of social networks. In this paper, we study changes in individual's affiliations on Twitter using natural language processing techniques and graph machine learning algorithms. In particular, we collected 9 million Twitter messages from 1.5 million users and constructed the retweet networks. We identified communities with explicit political orientation and topics of discussion associated to them which provide the topological representation of the political map on Twitter in the analyzed periods. With that data, we present a machine learning framework for social media users classification which efficiently detects "shifting users" (i.e. users that may change their affiliation over time). Moreover, this machine learning framework allows us to identify not only which topics are more persuasive (using low dimensional topic embedding), but also which individuals are more likely to change their affiliation given their topological properties in a Twitter graph.
Vocabulary-based Method for Quantifying Controversy in Social Media
Jan 14, 2020

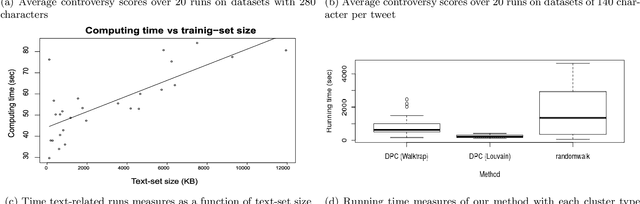
Identifying controversial topics is not only interesting from a social point of view, it also enables the application of methods to avoid the information segregation, creating better discussion contexts and reaching agreements in the best cases. In this paper we develop a systematic method for controversy detection based primarily on the jargon used by the communities in social media. Our method dispenses with the use of domain-specific knowledge, is language-agnostic, efficient and easy to apply. We perform an extensive set of experiments across many languages, regions and contexts, taking controversial and non-controversial topics. We find that our vocabulary-based measure performs better than state of the art measures that are based only on the community graph structure. Moreover, we shows that it is possible to detect polarization through text analysis.