 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubspaceAD: Training-Free Few-Shot Anomaly Detection via Subspace Modeling
Feb 26, 2026Detecting visual anomalies in industrial inspection often requires training with only a few normal images per category. Recent few-shot methods achieve strong results employing foundation-model features, but typically rely on memory banks, auxiliary datasets, or multi-modal tuning of vision-language models. We therefore question whether such complexity is necessary given the feature representations of vision foundation models. To answer this question, we introduce SubspaceAD, a training-free method, that operates in two simple stages. First, patch-level features are extracted from a small set of normal images by a frozen DINOv2 backbone. Second, a Principal Component Analysis (PCA) model is fit to these features to estimate the low-dimensional subspace of normal variations. At inference, anomalies are detected via the reconstruction residual with respect to this subspace, producing interpretable and statistically grounded anomaly scores. Despite its simplicity, SubspaceAD achieves state-of-the-art performance across one-shot and few-shot settings without training, prompt tuning, or memory banks. In the one-shot anomaly detection setting, SubspaceAD achieves image-level and pixel-level AUROC of 98.0% and 97.6% on the MVTec-AD dataset, and 93.3% and 98.3% on the VisA dataset, respectively, surpassing prior state-of-the-art results. Code and demo are available at https://github.com/CLendering/SubspaceAD.
TeG: Temporal-Granularity Method for Anomaly Detection with Attention in Smart City Surveillance
Nov 17, 2024Anomaly detection in video surveillance has recently gained interest from the research community. Temporal duration of anomalies vary within video streams, leading to complications in learning the temporal dynamics of specific events. This paper presents a temporal-granularity method for an anomaly detection model (TeG) in real-world surveillance, combining spatio-temporal features at different time-scales. The TeG model employs multi-head cross-attention blocks and multi-head self-attention blocks for this purpose. Additionally, we extend the UCF-Crime dataset with new anomaly types relevant to Smart City research project. The TeG model is deployed and validated in a city surveillance system, achieving successful real-time results in industrial settings.
MTFL: Multi-Timescale Feature Learning for Weakly-Supervised Anomaly Detection in Surveillance Videos
Oct 08, 2024



Detection of anomaly events is relevant for public safety and requires a combination of fine-grained motion information and contextual events at variable time-scales. To this end, we propose a Multi-Timescale Feature Learning (MTFL) method to enhance the representation of anomaly features. Short, medium, and long temporal tubelets are employed to extract spatio-temporal video features using a Video Swin Transformer. Experimental results demonstrate that MTFL outperforms state-of-the-art methods on the UCF-Crime dataset, achieving an anomaly detection performance 89.78% AUC. Moreover, it performs complementary to SotA with 95.32% AUC on the ShanghaiTech and 84.57% AP on the XD-Violence dataset. Furthermore, we generate an extended dataset of the UCF-Crime for development and evaluation on a wider range of anomalies, namely Video Anomaly Detection Dataset (VADD), involving 2,591 videos in 18 classes with extensive coverage of realistic anomalies.
Detection of Object Throwing Behavior in Surveillance Videos
Mar 11, 2024



Anomalous behavior detection is a challenging research area within computer vision. Progress in this area enables automated detection of dangerous behavior using surveillance camera feeds. A dangerous behavior that is often overlooked in other research is the throwing action in traffic flow, which is one of the unique requirements of our Smart City project to enhance public safety. This paper proposes a solution for throwing action detection in surveillance videos using deep learning. At present, datasets for throwing actions are not publicly available. To address the use-case of our Smart City project, we first generate the novel public 'Throwing Action' dataset, consisting of 271 videos of throwing actions performed by traffic participants, such as pedestrians, bicyclists, and car drivers, and 130 normal videos without throwing actions. Second, we compare the performance of different feature extractors for our anomaly detection method on the UCF-Crime and Throwing-Action datasets. The explored feature extractors are the Convolutional 3D (C3D) network, the Inflated 3D ConvNet (I3D) network, and the Multi-Fiber Network (MFNet). Finally, the performance of the anomaly detection algorithm is improved by applying the Adam optimizer instead of Adadelta, and proposing a mean normal loss function that covers the multitude of normal situations in traffic. Both aspects yield better anomaly detection performance. Besides this, the proposed mean normal loss function lowers the false alarm rate on the combined dataset. The experimental results reach an area under the ROC curve of 86.10 for the Throwing-Action dataset, and 80.13 on the combined dataset, respectively.
Density-Guided Label Smoothing for Temporal Localization of Driving Actions
Mar 11, 2024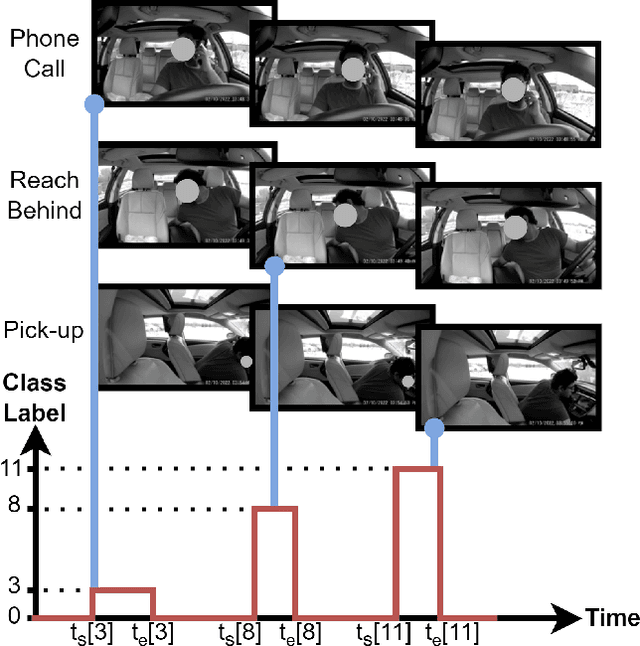
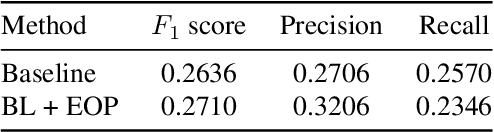
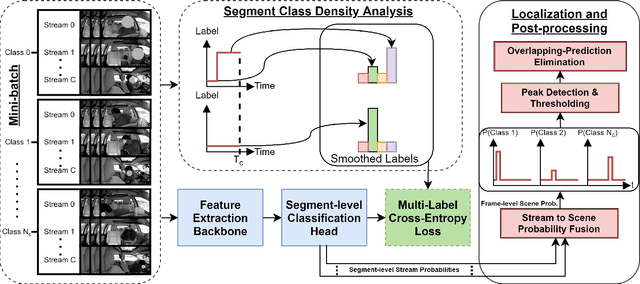
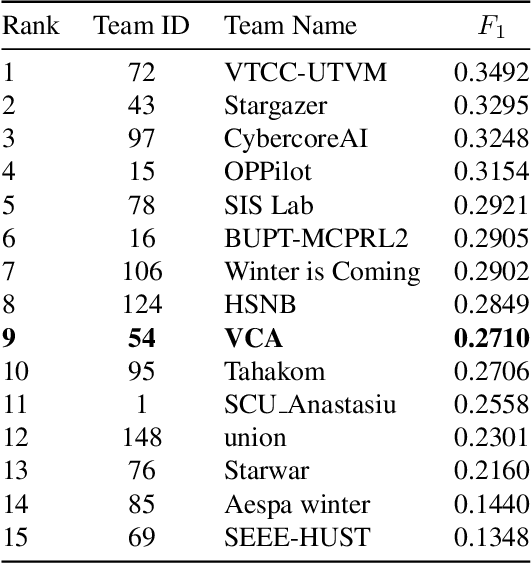
Temporal localization of driving actions plays a crucial role in advanced driver-assistance systems and naturalistic driving studies. However, this is a challenging task due to strict requirements for robustness, reliability and accurate localization. In this work, we focus on improving the overall performance by efficiently utilizing video action recognition networks and adapting these to the problem of action localization. To this end, we first develop a density-guided label smoothing technique based on label probability distributions to facilitate better learning from boundary video-segments that typically include multiple labels. Second, we design a post-processing step to efficiently fuse information from video-segments and multiple camera views into scene-level predictions, which facilitates elimination of false positives. Our methodology yields a competitive performance on the A2 test set of the naturalistic driving action recognition track of the 2022 NVIDIA AI City Challenge with an F1 score of 0.271.
Transformer-based Fusion of 2D-pose and Spatio-temporal Embeddings for Distracted Driver Action Recognition
Mar 11, 2024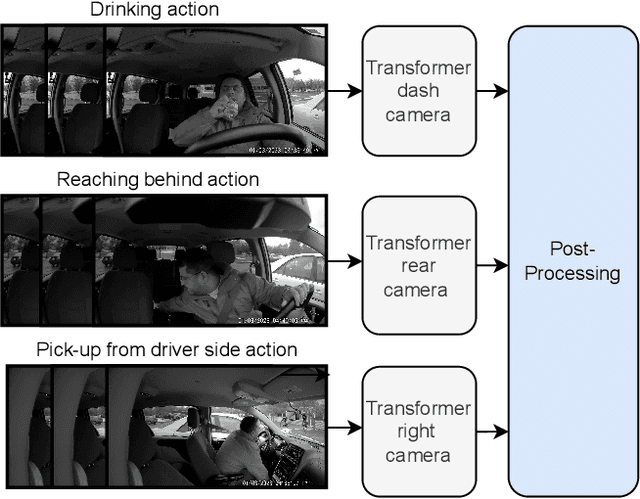
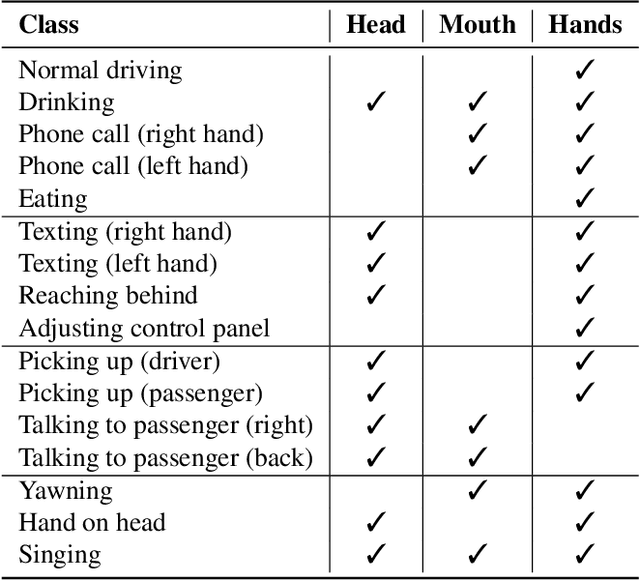
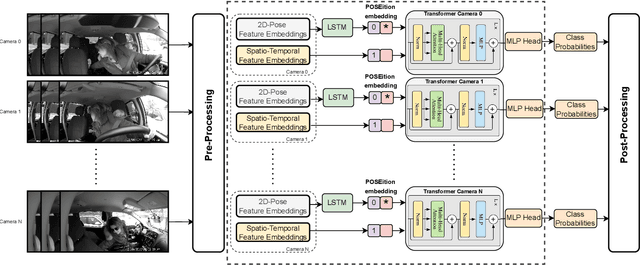
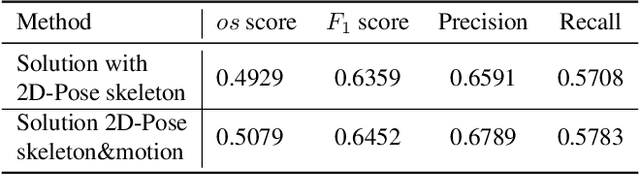
Classification and localization of driving actions over time is important for advanced driver-assistance systems and naturalistic driving studies. Temporal localization is challenging because it requires robustness, reliability, and accuracy. In this study, we aim to improve the temporal localization and classification accuracy performance by adapting video action recognition and 2D human-pose estimation networks to one model. Therefore, we design a transformer-based fusion architecture to effectively combine 2D-pose features and spatio-temporal features. The model uses 2D-pose features as the positional embedding of the transformer architecture and spatio-temporal features as the main input to the encoder of the transformer. The proposed solution is generic and independent of the camera numbers and positions, giving frame-based class probabilities as output. Finally, the post-processing step combines information from different camera views to obtain final predictions and eliminate false positives. The model performs well on the A2 test set of the 2023 NVIDIA AI City Challenge for naturalistic driving action recognition, achieving the overlap score of the organizer-defined distracted driver behaviour metric of 0.5079.