 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartitioned Learned Bloom Filter
Jun 05, 2020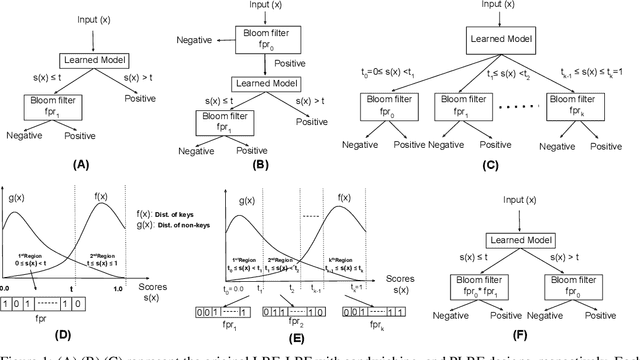
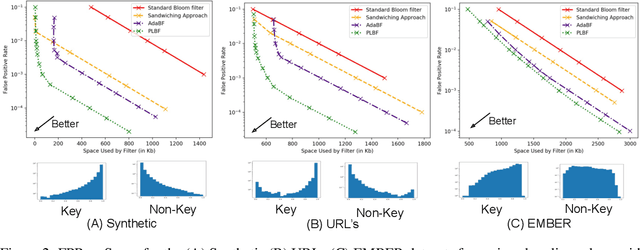
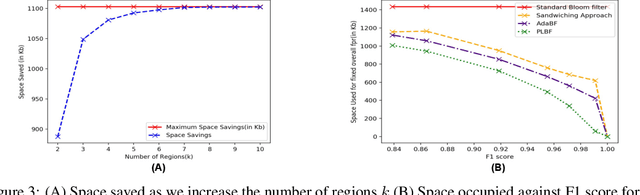
Learned Bloom filters enhance standard Bloom filters by using a learned model for the represented data set. However, a learned Bloom filter may under-utilize the model by not taking full advantage of the output. The learned Bloom filter uses the output score by simply applying a threshold, with elements above the threshold being interpreted as positives, and elements below the threshold subject to further analysis independent of the output score (using a smaller backup Bloom filter to prevent false negatives). While recent work has suggested additional heuristic approaches to take better advantage of the score, the results are only heuristic. Here, we instead frame the problem of optimal model utilization as an optimization problem. We show that the optimization problem can be effectively solved efficiently, yielding an improved {partitioned learned Bloom filter}, which partitions the score space and utilizes separate backup Bloom filters for each region. Experimental results from both simulated and real-world datasets show significant performance improvements from our optimization approach over both the original learned Bloom filter constructions and previously proposed heuristic improvements.