 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning of Generic and User-Focused Summarization
Nov 02, 1998

A key problem in text summarization is finding a salience function which determines what information in the source should be included in the summary. This paper describes the use of machine learning on a training corpus of documents and their abstracts to discover salience functions which describe what combination of features is optimal for a given summarization task. The method addresses both "generic" and user-focused summaries.
Machine Learning of User Profiles: Representational Issues
Dec 11, 1997


As more information becomes available electronically, tools for finding information of interest to users becomes increasingly important. The goal of the research described here is to build a system for generating comprehensible user profiles that accurately capture user interest with minimum user interaction. The research described here focuses on the importance of a suitable generalization hierarchy and representation for learning profiles which are predictively accurate and comprehensible. In our experiments we evaluated both traditional features based on weighted term vectors as well as subject features corresponding to categories which could be drawn from a thesaurus. Our experiments, conducted in the context of a content-based profiling system for on-line newspapers on the World Wide Web (the IDD News Browser), demonstrate the importance of a generalization hierarchy and the promise of combining natural language processing techniques with machine learning (ML) to address an information retrieval (IR) problem.
Multi-document Summarization by Graph Search and Matching
Dec 10, 1997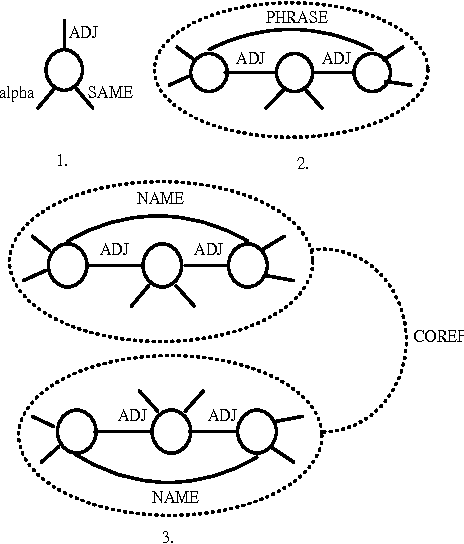


We describe a new method for summarizing similarities and differences in a pair of related documents using a graph representation for text. Concepts denoted by words, phrases, and proper names in the document are represented positionally as nodes in the graph along with edges corresponding to semantic relations between items. Given a perspective in terms of which the pair of documents is to be summarized, the algorithm first uses a spreading activation technique to discover, in each document, nodes semantically related to the topic. The activated graphs of each document are then matched to yield a graph corresponding to similarities and differences between the pair, which is rendered in natural language. An evaluation of these techniques has been carried out.