 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-document Summarization by Graph Search and Matching
Paper and Code
Dec 10, 1997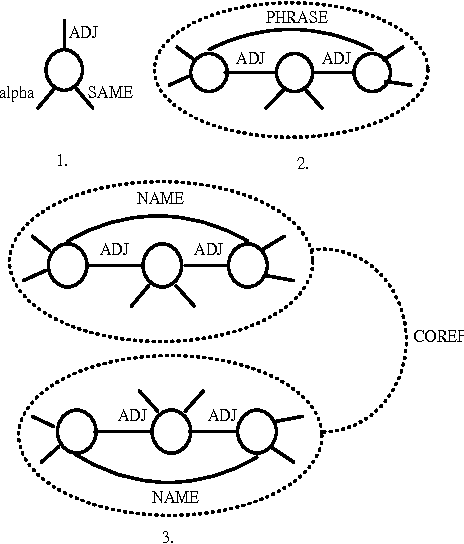


We describe a new method for summarizing similarities and differences in a pair of related documents using a graph representation for text. Concepts denoted by words, phrases, and proper names in the document are represented positionally as nodes in the graph along with edges corresponding to semantic relations between items. Given a perspective in terms of which the pair of documents is to be summarized, the algorithm first uses a spreading activation technique to discover, in each document, nodes semantically related to the topic. The activated graphs of each document are then matched to yield a graph corresponding to similarities and differences between the pair, which is rendered in natural language. An evaluation of these techniques has been carried out.