 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient K-means Clustering Algorithm for Analysing COVID-19
Dec 21, 2020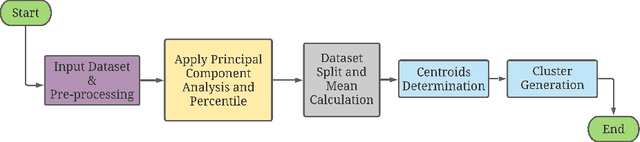
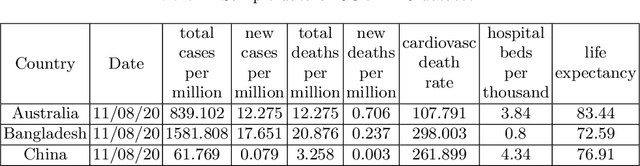
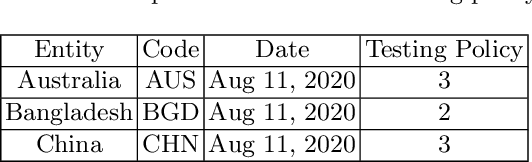
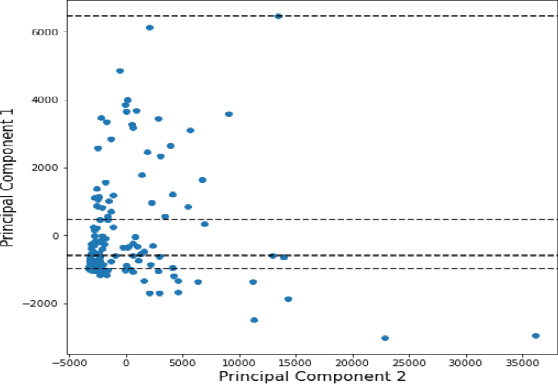
COVID-19 hits the world like a storm by arising pandemic situations for most of the countries around the world. The whole world is trying to overcome this pandemic situation. A better health care quality may help a country to tackle the pandemic. Making clusters of countries with similar types of health care quality provides an insight into the quality of health care in different countries. In the area of machine learning and data science, the K-means clustering algorithm is typically used to create clusters based on similarity. In this paper, we propose an efficient K-means clustering method that determines the initial centroids of the clusters efficiently. Based on this proposed method, we have determined health care quality clusters of countries utilizing the COVID-19 datasets. Experimental results show that our proposed method reduces the number of iterations and execution time to analyze COVID-19 while comparing with the traditional k-means clustering algorithm.
Predicting Individual Substance Abuse Vulnerability using Machine Learning Techniques
Dec 09, 2020Substance abuse is the unrestrained and detrimental use of psychoactive chemical substances, unauthorized drugs, and alcohol. Continuous use of these substances can ultimately lead a human to disastrous consequences. As patients display a high rate of relapse, prevention at an early stage can be an effective restraint. We therefore propose a binary classifier to identify any individual's present vulnerability towards substance abuse by analyzing subjects' socio-economic environment. We have collected data by a questionnaire which is created after carefully assessing the commonly involved factors behind substance abuse. Pearson's chi-squared test of independence is used to identify key feature variables influencing substance abuse. Later we build the predictive classifiers using machine learning classification algorithms on those variables. Logistic regression classifier trained with 18 features can predict individual vulnerability with the best accuracy.