 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parallel/Distributed Algorithmic Framework for Mining All Quantitative Association Rules
Apr 18, 2018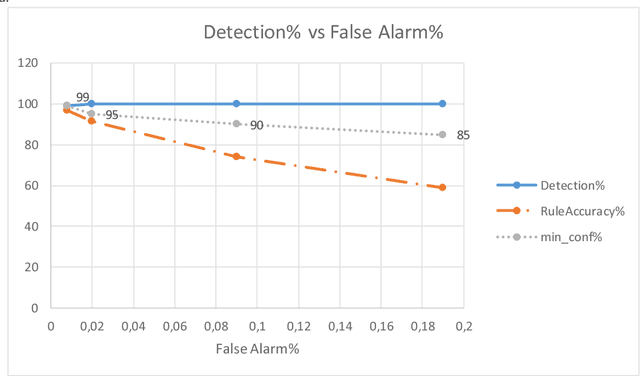
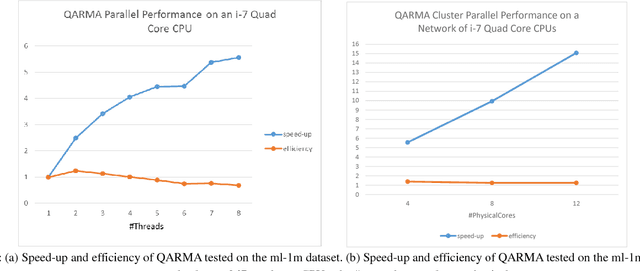
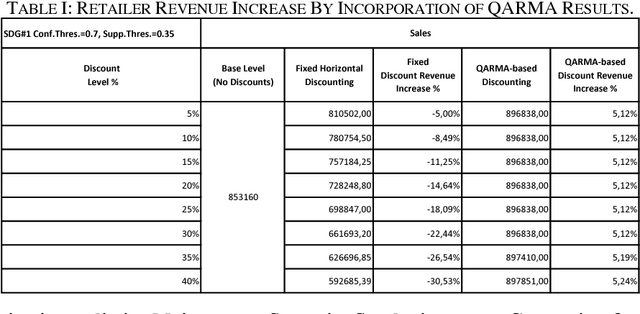
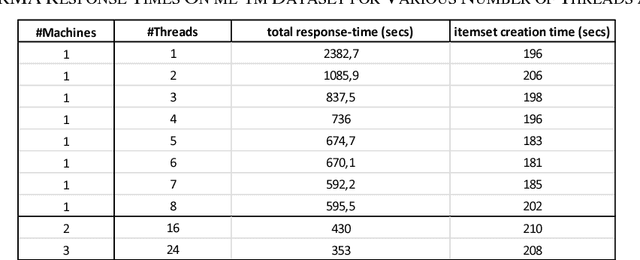
We present QARMA, an efficient novel parallel algorithm for mining all Quantitative Association Rules in large multidimensional datasets where items are required to have at least a single common attribute to be specified in the rules single consequent item. Given a minimum support level and a set of threshold criteria of interestingness measures such as confidence, conviction etc. our algorithm guarantees the generation of all non-dominated Quantitative Association Rules that meet the minimum support and interestingness requirements. Such rules can be of great importance to marketing departments seeking to optimize targeted campaigns, or general market segmentation. They can also be of value in medical applications, financial as well as predictive maintenance domains. We provide computational results showing the scalability of our algorithm, and its capability to produce all rules to be found in large scale synthetic and real world datasets such as Movie Lens, within a few seconds or minutes of computational time on commodity hardware.