 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Intrusion Response System utilizing Deep Q-Networks and System Partitions
Feb 16, 2022

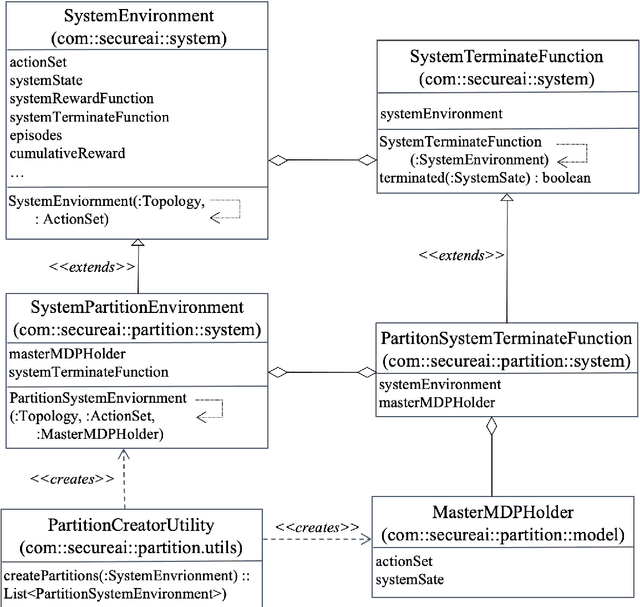
Intrusion Response is a relatively new field of research. Recent approaches for the creation of Intrusion Response Systems (IRSs) use Reinforcement Learning (RL) as a primary technique for the optimal or near-optimal selection of the proper countermeasure to take in order to stop or mitigate an ongoing attack. However, most of them do not consider the fact that systems can change over time or, in other words, that systems exhibit a non-stationary behavior. Furthermore, stateful approaches, such as those based on RL, suffer the curse of dimensionality, due to a state space growing exponentially with the size of the protected system. In this paper, we introduce and develop an IRS software prototype, named irs-partition. It leverages the partitioning of the protected system and Deep Q-Networks to address the curse of dimensionality by supporting a multi-agent formulation. Furthermore, it exploits transfer learning to follow the evolution of non-stationary systems.
Hoeffding Trees with nmin adaptation
Aug 03, 2018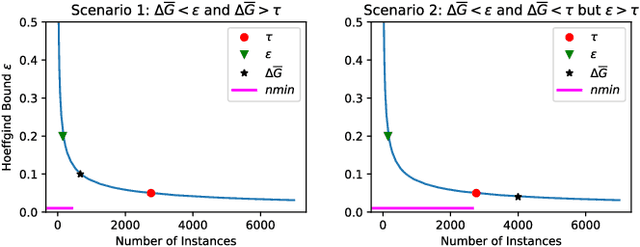
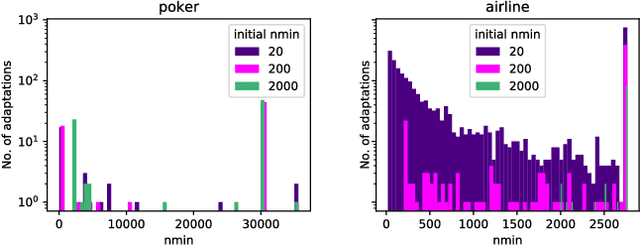
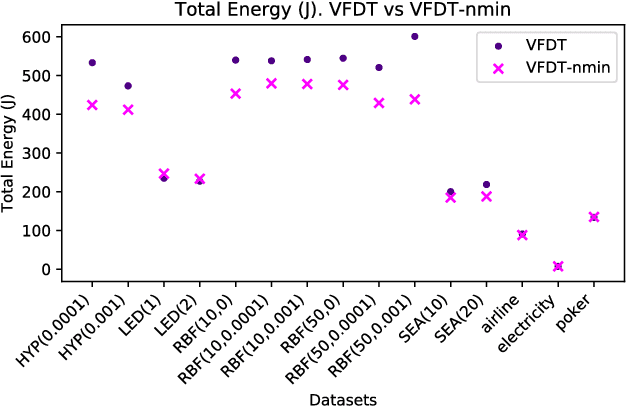

Machine learning software accounts for a significant amount of energy consumed in data centers. These algorithms are usually optimized towards predictive performance, i.e. accuracy, and scalability. This is the case of data stream mining algorithms. Although these algorithms are adaptive to the incoming data, they have fixed parameters from the beginning of the execution. We have observed that having fixed parameters lead to unnecessary computations, thus making the algorithm energy inefficient. In this paper we present the nmin adaptation method for Hoeffding trees. This method adapts the value of the nmin parameter, which significantly affects the energy consumption of the algorithm. The method reduces unnecessary computations and memory accesses, thus reducing the energy, while the accuracy is only marginally affected. We experimentally compared VFDT (Very Fast Decision Tree, the first Hoeffding tree algorithm) and CVFDT (Concept-adapting VFDT) with the VFDT-nmin (VFDT with nmin adaptation). The results show that VFDT-nmin consumes up to 27% less energy than the standard VFDT, and up to 92% less energy than CVFDT, trading off a few percent of accuracy in a few datasets.