 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAiding Global Convergence in Federated Learning via Local Perturbation and Mutual Similarity Information
Oct 07, 2024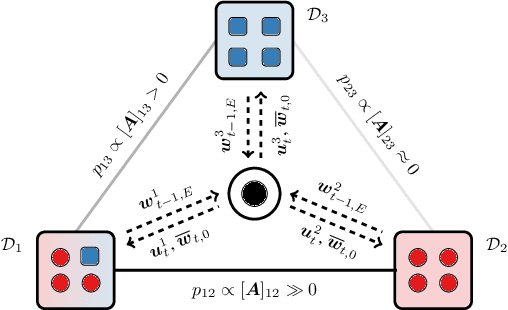

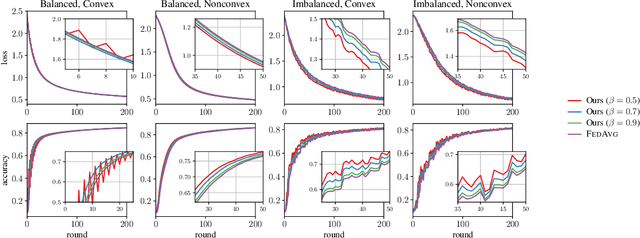
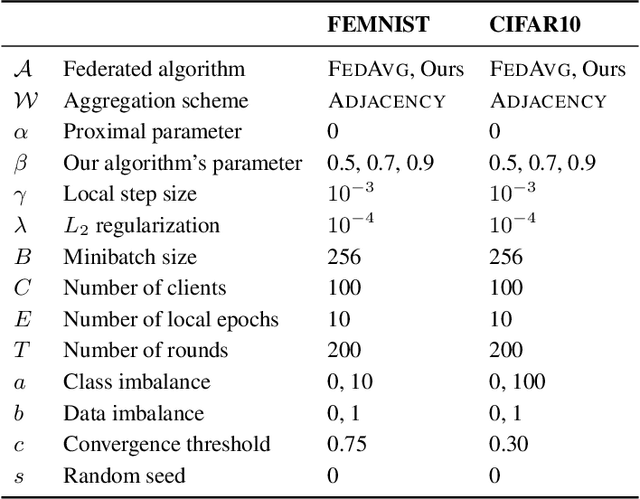
Federated learning has emerged in the last decade as a distributed optimization paradigm due to the rapidly increasing number of portable devices able to support the heavy computational needs related to the training of machine learning models. Federated learning utilizes gradient-based optimization to minimize a loss objective shared across participating agents. To the best of our knowledge, the literature mostly lacks elegant solutions that naturally harness the reciprocal statistical similarity between clients to redesign the optimization procedure. To address this gap, by conceiving the federated network as a similarity graph, we propose a novel modified framework wherein each client locally performs a perturbed gradient step leveraging prior information about other statistically affine clients. We theoretically prove that our procedure, due to a suitably introduced adaptation in the update rule, achieves a quantifiable speedup concerning the exponential contraction factor in the strongly convex case compared with popular algorithms FedAvg and FedProx, here analyzed as baselines. Lastly, we legitimize our conclusions through experimental results on the CIFAR10 and FEMNIST datasets, where we show that our algorithm speeds convergence up to a margin of 30 global rounds compared with FedAvg while modestly improving generalization on unseen data in heterogeneous settings.