 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Barycenters of Persistence Diagrams
Sep 18, 2025
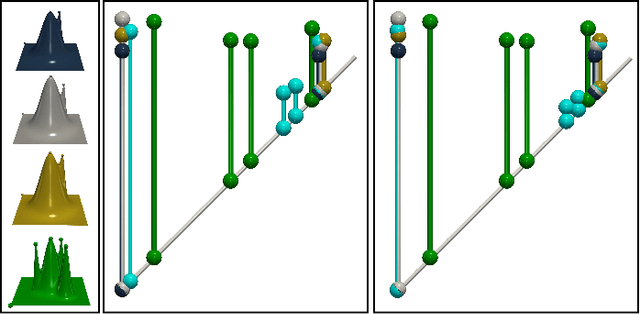
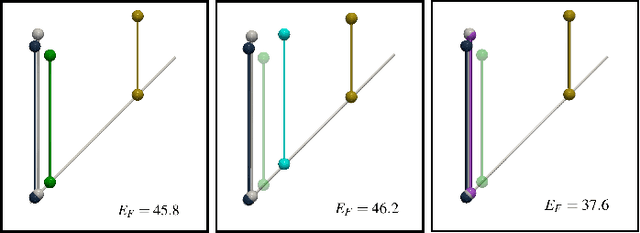
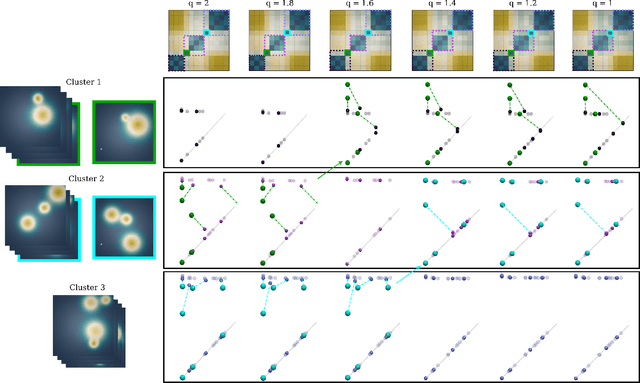
This short paper presents a general approach for computing robust Wasserstein barycenters of persistence diagrams. The classical method consists in computing assignment arithmetic means after finding the optimal transport plans between the barycenter and the persistence diagrams. However, this procedure only works for the transportation cost related to the $q$-Wasserstein distance $W_q$ when $q=2$. We adapt an alternative fixed-point method to compute a barycenter diagram for generic transportation costs ($q > 1$), in particular those robust to outliers, $q \in (1,2)$. We show the utility of our work in two applications: \emph{(i)} the clustering of persistence diagrams on their metric space and \emph{(ii)} the dictionary encoding of persistence diagrams. In both scenarios, we demonstrate the added robustness to outliers provided by our generalized framework. Our Python implementation is available at this address: https://github.com/Keanu-Sisouk/RobustBarycenter .
Convergence of SGD for Training Neural Networks with Sliced Wasserstein Losses
Jul 21, 2023Optimal Transport has sparked vivid interest in recent years, in particular thanks to the Wasserstein distance, which provides a geometrically sensible and intuitive way of comparing probability measures. For computational reasons, the Sliced Wasserstein (SW) distance was introduced as an alternative to the Wasserstein distance, and has seen uses for training generative Neural Networks (NNs). While convergence of Stochastic Gradient Descent (SGD) has been observed practically in such a setting, there is to our knowledge no theoretical guarantee for this observation. Leveraging recent works on convergence of SGD on non-smooth and non-convex functions by Bianchi et al. (2022), we aim to bridge that knowledge gap, and provide a realistic context under which fixed-step SGD trajectories for the SW loss on NN parameters converge. More precisely, we show that the trajectories approach the set of (sub)-gradient flow equations as the step decreases. Under stricter assumptions, we show a much stronger convergence result for noised and projected SGD schemes, namely that the long-run limits of the trajectories approach a set of generalised critical points of the loss function.
Properties of Discrete Sliced Wasserstein Losses
Jul 19, 2023The Sliced Wasserstein (SW) distance has become a popular alternative to the Wasserstein distance for comparing probability measures. Widespread applications include image processing, domain adaptation and generative modelling, where it is common to optimise some parameters in order to minimise SW, which serves as a loss function between discrete probability measures (since measures admitting densities are numerically unattainable). All these optimisation problems bear the same sub-problem, which is minimising the Sliced Wasserstein energy. In this paper we study the properties of $\mathcal{E}: Y \longmapsto \mathrm{SW}_2^2(\gamma_Y, \gamma_Z)$, i.e. the SW distance between two uniform discrete measures with the same amount of points as a function of the support $Y \in \mathbb{R}^{n \times d}$ of one of the measures. We investigate the regularity and optimisation properties of this energy, as well as its Monte-Carlo approximation $\mathcal{E}_p$ (estimating the expectation in SW using only $p$ samples) and show convergence results on the critical points of $\mathcal{E}_p$ to those of $\mathcal{E}$, as well as an almost-sure uniform convergence. Finally, we show that in a certain sense, Stochastic Gradient Descent methods minimising $\mathcal{E}$ and $\mathcal{E}_p$ converge towards (Clarke) critical points of these energies.