 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Federated Representations and Recommendations with Limited Negatives
Aug 18, 2021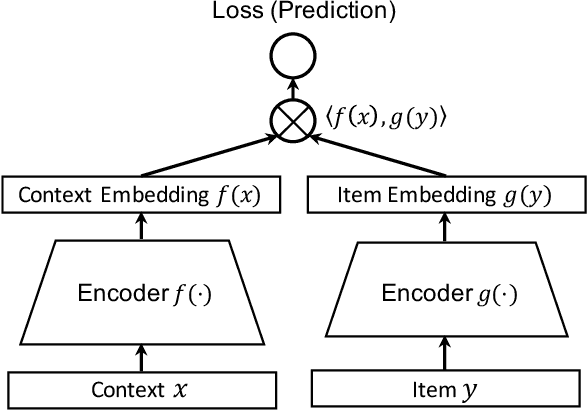
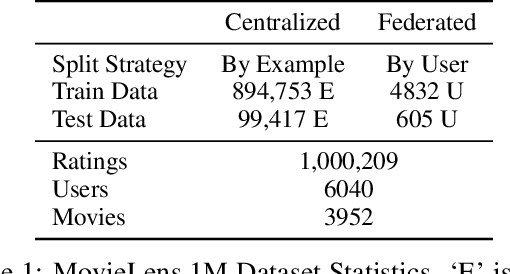
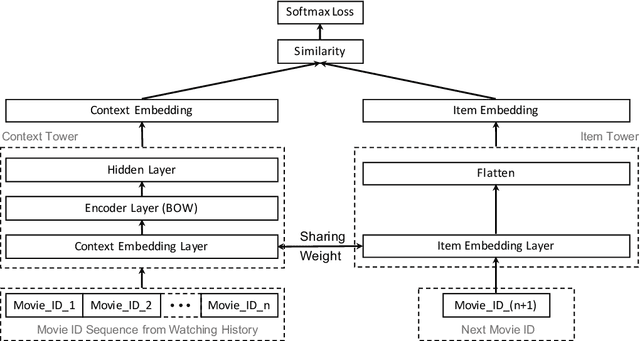

Deep retrieval models are widely used for learning entity representations and recommendations. Federated learning provides a privacy-preserving way to train these models without requiring centralization of user data. However, federated deep retrieval models usually perform much worse than their centralized counterparts due to non-IID (independent and identically distributed) training data on clients, an intrinsic property of federated learning that limits negatives available for training. We demonstrate that this issue is distinct from the commonly studied client drift problem. This work proposes batch-insensitive losses as a way to alleviate the non-IID negatives issue for federated movie recommendation. We explore a variety of techniques and identify that batch-insensitive losses can effectively improve the performance of federated deep retrieval models, increasing the relative recall of the federated model by up to 93.15% and reducing the relative gap in recall between it and a centralized model from 27.22% - 43.14% to 0.53% - 2.42%. We open-source our code framework to accelerate further research and applications of federated deep retrieval models.