 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Bill Similarity with Annotated and Augmented Corpora of Bills
Sep 14, 2021

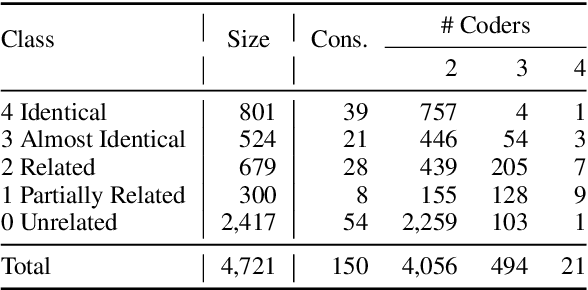

Bill writing is a critical element of representative democracy. However, it is often overlooked that most legislative bills are derived, or even directly copied, from other bills. Despite the significance of bill-to-bill linkages for understanding the legislative process, existing approaches fail to address semantic similarities across bills, let alone reordering or paraphrasing which are prevalent in legal document writing. In this paper, we overcome these limitations by proposing a 5-class classification task that closely reflects the nature of the bill generation process. In doing so, we construct a human-labeled dataset of 4,721 bill-to-bill relationships at the subsection-level and release this annotated dataset to the research community. To augment the dataset, we generate synthetic data with varying degrees of similarity, mimicking the complex bill writing process. We use BERT variants and apply multi-stage training, sequentially fine-tuning our models with synthetic and human-labeled datasets. We find that the predictive performance significantly improves when training with both human-labeled and synthetic data. Finally, we apply our trained model to infer section- and bill-level similarities. Our analysis shows that the proposed methodology successfully captures the similarities across legal documents at various levels of aggregation.