 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural language processing for clusterization of genes according to their functions
Jul 17, 2022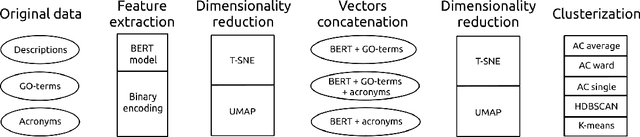
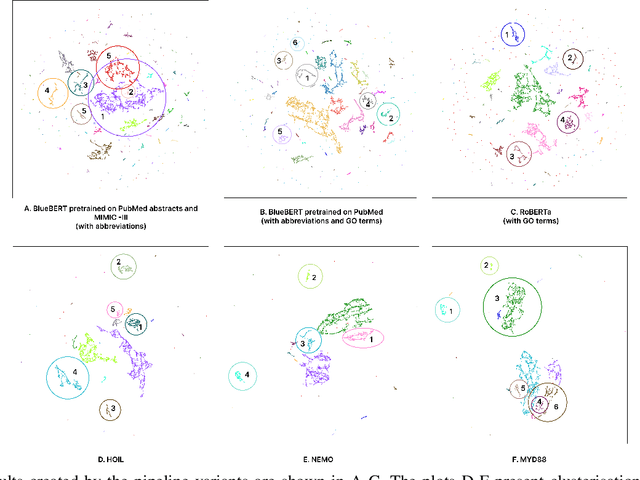
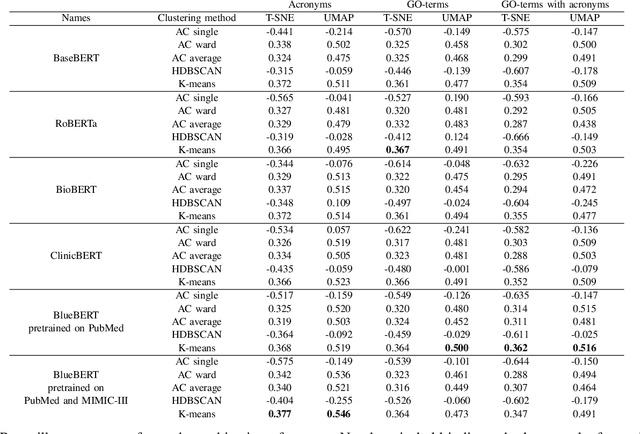
There are hundreds of methods for analysis of data obtained in mRNA-sequencing. The most of them are focused on small number of genes. In this study, we propose an approach that reduces the analysis of several thousand genes to analysis of several clusters. The list of genes is enriched with information from open databases. Then, the descriptions are encoded as vectors using the pretrained language model (BERT) and some text processing approaches. The encoded gene function pass through the dimensionality reduction and clusterization. Aiming to find the most efficient pipeline, 180 cases of pipeline with different methods in the major pipeline steps were analyzed. The performance was evaluated with clusterization indexes and expert review of the results.