 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint-less: More Abstractive Summarization with Pointer-Generator Networks
Apr 18, 2019

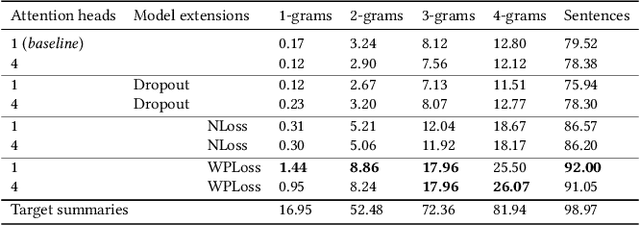

The Pointer-Generator architecture has shown to be a big improvement for abstractive summarization seq2seq models. However, the summaries produced by this model are largely extractive as over 30% of the generated sentences are copied from the source text. This work proposes a multihead attention mechanism, pointer dropout, and two new loss functions to promote more abstractive summaries while maintaining similar ROUGE scores. Both the multihead attention and dropout do not improve N-gram novelty, however, the dropout acts as a regularizer which improves the ROUGE score. The new loss function achieves significantly higher novel N-grams and sentences, at the cost of a slightly lower ROUGE score.
Optical Music Recognition with Convolutional Sequence-to-Sequence Models
Jul 16, 2017
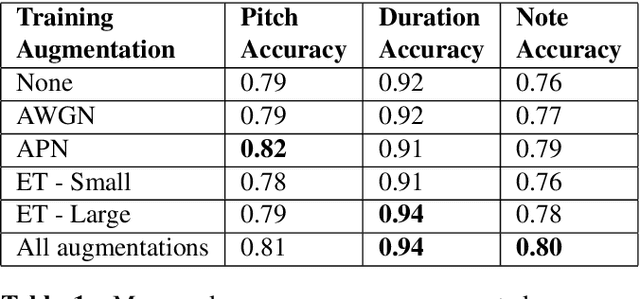
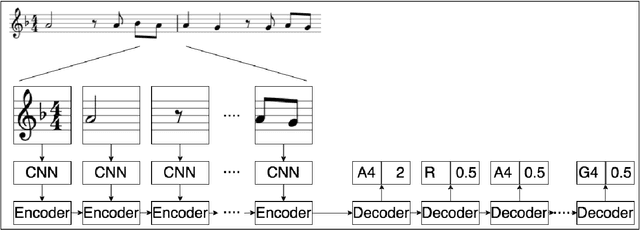
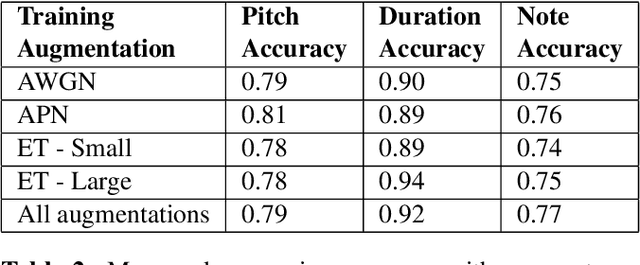
Optical Music Recognition (OMR) is an important technology within Music Information Retrieval. Deep learning models show promising results on OMR tasks, but symbol-level annotated data sets of sufficient size to train such models are not available and difficult to develop. We present a deep learning architecture called a Convolutional Sequence-to-Sequence model to both move towards an end-to-end trainable OMR pipeline, and apply a learning process that trains on full sentences of sheet music instead of individually labeled symbols. The model is trained and evaluated on a human generated data set, with various image augmentations based on real-world scenarios. This data set is the first publicly available set in OMR research with sufficient size to train and evaluate deep learning models. With the introduced augmentations a pitch recognition accuracy of 81% and a duration accuracy of 94% is achieved, resulting in a note level accuracy of 80%. Finally, the model is compared to commercially available methods, showing a large improvements over these applications.