 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText recognition on images using pre-trained CNN
Feb 10, 2023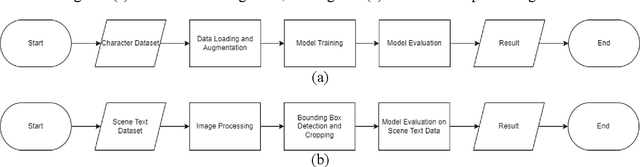
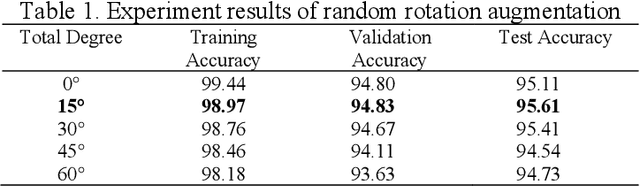

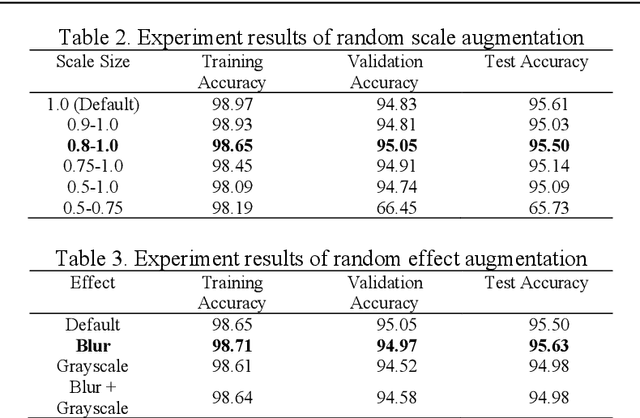
A text on an image often stores important information and directly carries high level semantics, makes it as important source of information and become a very active research topic. Many studies have shown that the use of CNN-based neural networks is quite effective and accurate for image classification which is the basis of text recognition. It can also be more enhanced by using transfer learning from pre-trained model trained on ImageNet dataset as an initial weight. In this research, the recognition is trained by using Chars74K dataset and the best model results then tested on some samples of IIIT-5K-Dataset. The research results showed that the best accuracy is the model that trained using VGG-16 architecture applied with image transformation of rotation 15{\deg}, image scale of 0.9, and the application of gaussian blur effect. The research model has an accuracy of 97.94% for validation data, 98.16% for test data, and 95.62% for the test data from IIIT-5K-Dataset. Based on these results, it can be concluded that pre-trained CNN can produce good accuracy for text recognition, and the model architecture that used in this study can be used as reference material in the development of text detection systems in the future
Prediction of COVID-19 by Its Variants using Multivariate Data-driven Deep Learning Models
Jan 28, 2023The Coronavirus Disease 2019 or the COVID-19 pandemic has swept almost all parts of the world since the first case was found in Wuhan, China, in December 2019. With the increasing number of COVID-19 cases in the world, SARS-CoV-2 has mutated into various variants. Given the increasingly dangerous conditions of the pandemic, it is crucial to know when the pandemic will stop by predicting confirmed cases of COVID-19. Therefore, many studies have raised COVID-19 as a case study to overcome the ongoing pandemic using the Deep Learning method, namely LSTM, with reasonably accurate results and small error values. LSTM training is used to predict confirmed cases of COVID-19 based on variants that have been identified using ECDC's COVID-19 dataset containing confirmed cases of COVID-19 that have been identified from 30 countries in Europe. Tests were conducted using the LSTM and BiLSTM models with the addition of RNN as comparisons on hidden size and layer size. The obtained result showed that in testing hidden sizes 25, 50, 75 to 100, the RNN model provided better results, with the minimum MSE value of 0.01 and the RMSE value of 0.012 for B.1.427/B.1.429 variant with hidden size 100. In further testing of layer sizes 2, 3, 4, and 5, the result shows that the BiLSTM model provided better results, with minimum MSE value of 0.01 and the RMSE of 0.01 for the B.1.427/B.1.429 variant with hidden size 100 and layer size 2.