 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuOTeS: Query-Oriented Technical Summarization
Jun 20, 2023Abstract. When writing an academic paper, researchers often spend considerable time reviewing and summarizing papers to extract relevant citations and data to compose the Introduction and Related Work sections. To address this problem, we propose QuOTeS, an interactive system designed to retrieve sentences related to a summary of the research from a collection of potential references and hence assist in the composition of new papers. QuOTeS integrates techniques from Query-Focused Extractive Summarization and High-Recall Information Retrieval to provide Interactive Query-Focused Summarization of scientific documents. To measure the performance of our system, we carried out a comprehensive user study where participants uploaded papers related to their research and evaluated the system in terms of its usability and the quality of the summaries it produces. The results show that QuOTeS provides a positive user experience and consistently provides query-focused summaries that are relevant, concise, and complete. We share the code of our system and the novel Query-Focused Summarization dataset collected during our experiments at https://github.com/jarobyte91/quotes.
Post-OCR Document Correction with large Ensembles of Character Sequence Models
Sep 15, 2021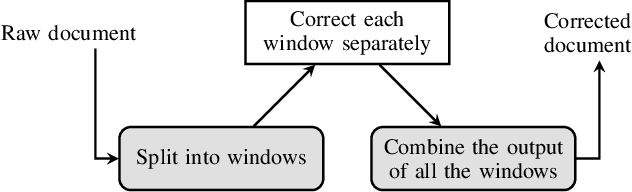
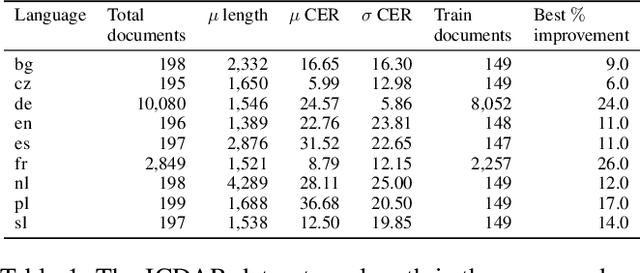
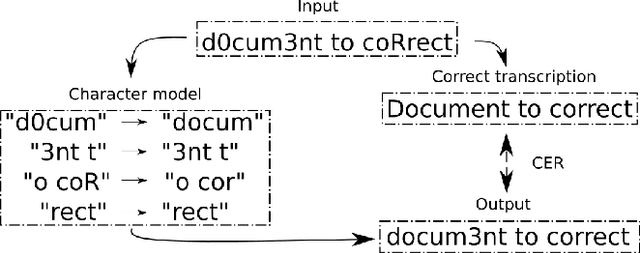
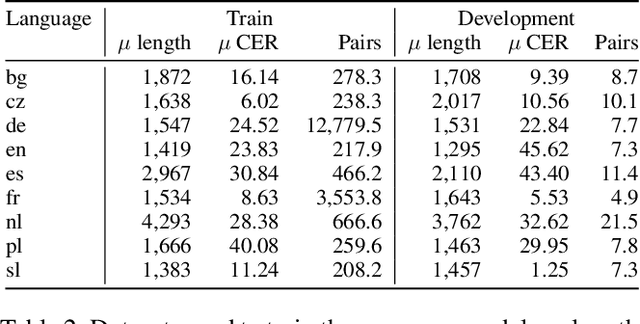
In this paper, we propose a novel method based on character sequence-to-sequence models to correct documents already processed with Optical Character Recognition (OCR) systems. The main contribution of this paper is a set of strategies to accurately process strings much longer than the ones used to train the sequence model while being sample- and resource-efficient, supported by thorough experimentation. The strategy with the best performance involves splitting the input document in character n-grams and combining their individual corrections into the final output using a voting scheme that is equivalent to an ensemble of a large number of sequence models. We further investigate how to weigh the contributions from each one of the members of this ensemble. We test our method on nine languages of the ICDAR 2019 competition on post-OCR text correction and achieve a new state-of-the-art performance in five of them. Our code for post-OCR correction is shared at https://github.com/jarobyte91/post_ocr_correction.