 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow social feedback processing in the brain shapes collective opinion processes in the era of social media
Mar 18, 2020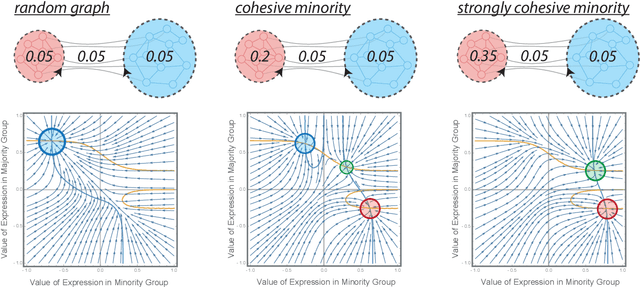
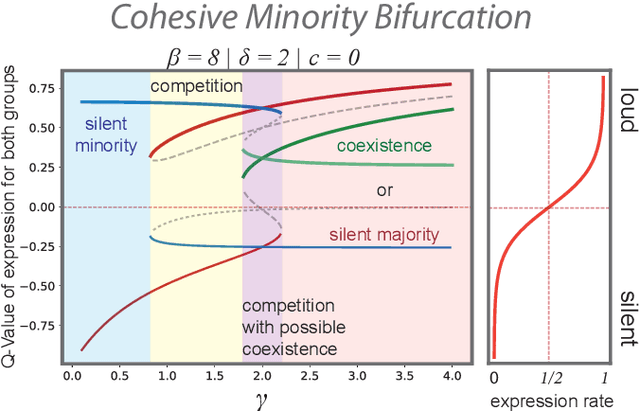

What are the mechanisms by which groups with certain opinions gain public voice and force others holding a different view into silence? And how does social media play into this? Drawing on recent neuro-scientific insights into the processing of social feedback, we develop a theoretical model that allows to address these questions. The model captures phenomena described by spiral of silence theory of public opinion, provides a mechanism-based foundation for it, and allows in this way more general insight into how different group structures relate to different regimes of collective opinion expression. Even strong majorities can be forced into silence if a minority acts as a cohesive whole. The proposed framework of social feedback theory (SFT) highlights the need for sociological theorising to understand the societal-level implications of findings in social and cognitive neuroscience.
Opinion Polarization by Learning from Social Feedback
Oct 19, 2018
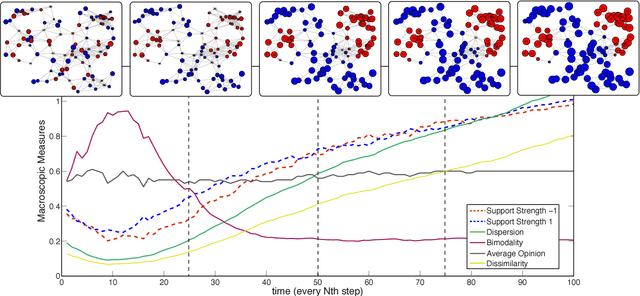

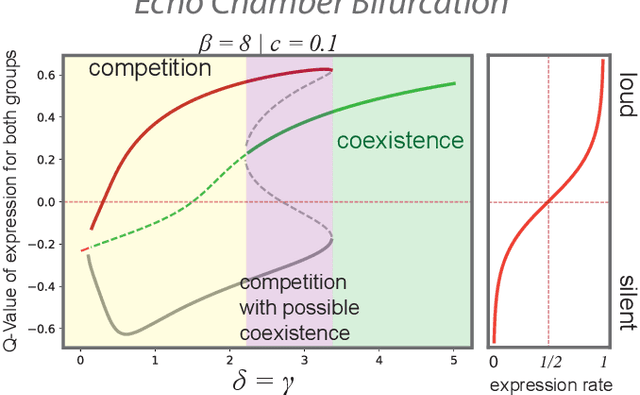
We explore a new mechanism to explain polarization phenomena in opinion dynamics in which agents evaluate alternative views on the basis of the social feedback obtained on expressing them. High support of the favored opinion in the social environment, is treated as a positive feedback which reinforces the value associated to this opinion. In connected networks of sufficiently high modularity, different groups of agents can form strong convictions of competing opinions. Linking the social feedback process to standard equilibrium concepts we analytically characterize sufficient conditions for the stability of bi-polarization. While previous models have emphasized the polarization effects of deliberative argument-based communication, our model highlights an affective experience-based route to polarization, without assumptions about negative influence or bounded confidence.
* Presented at the Social Simulation Conference (Dublin 2017)
The Coconut Model with Heterogeneous Strategies and Learning
Dec 01, 2016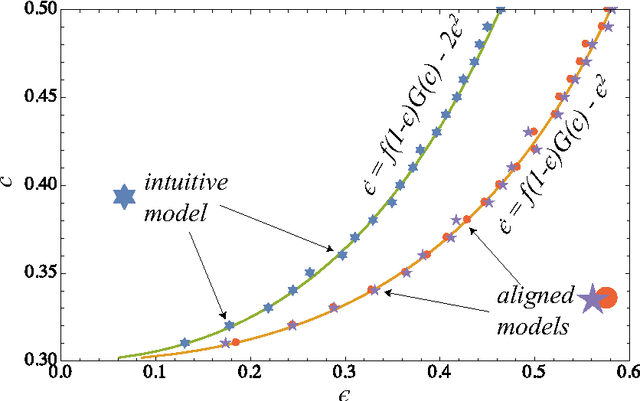
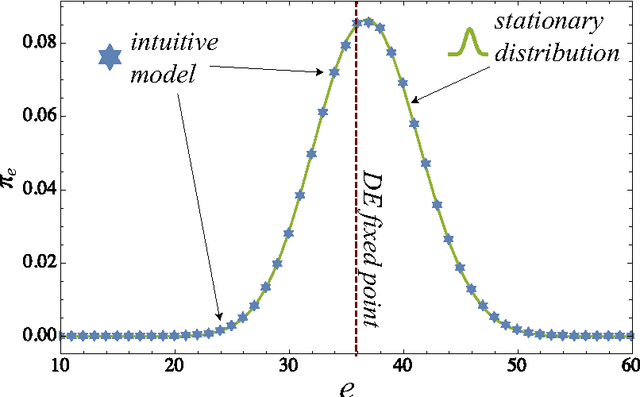
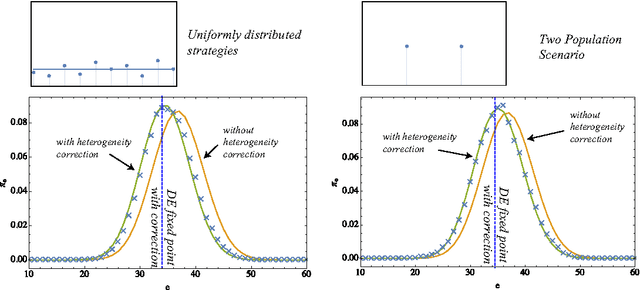
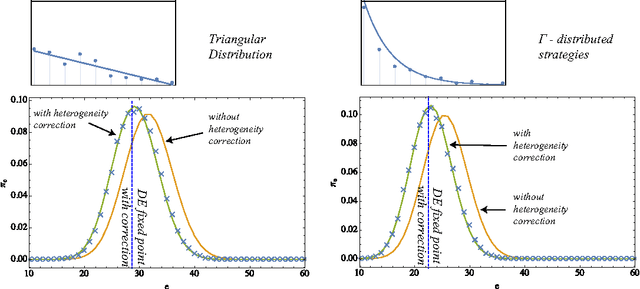
In this paper, we develop an agent-based version of the Diamond search equilibrium model - also called Coconut Model. In this model, agents are faced with production decisions that have to be evaluated based on their expectations about the future utility of the produced entity which in turn depends on the global production level via a trading mechanism. While the original dynamical systems formulation assumes an infinite number of homogeneously adapting agents obeying strong rationality conditions, the agent-based setting allows to discuss the effects of heterogeneous and adaptive expectations and enables the analysis of non-equilibrium trajectories. Starting from a baseline implementation that matches the asymptotic behavior of the original model, we show how agent heterogeneity can be accounted for in the aggregate dynamical equations. We then show that when agents adapt their strategies by a simple temporal difference learning scheme, the system converges to one of the fixed points of the original system. Systematic simulations reveal that this is the only stable equilibrium solution.
Quantifying Emergent Behavior of Autonomous Robots
Oct 06, 2015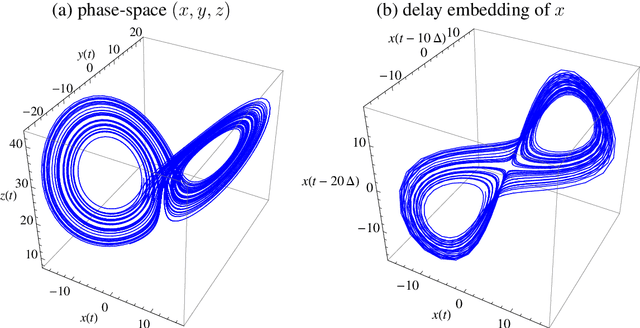

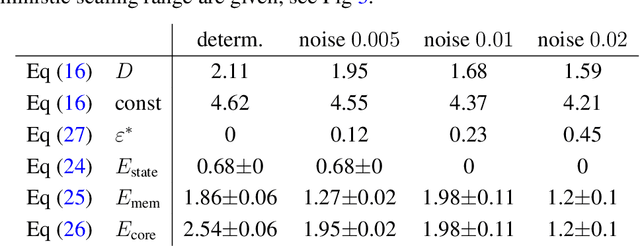
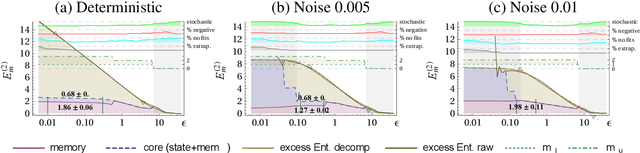
Quantifying behaviors of robots which were generated autonomously from task-independent objective functions is an important prerequisite for objective comparisons of algorithms and movements of animals. The temporal sequence of such a behavior can be considered as a time series and hence complexity measures developed for time series are natural candidates for its quantification. The predictive information and the excess entropy are such complexity measures. They measure the amount of information the past contains about the future and thus quantify the nonrandom structure in the temporal sequence. However, when using these measures for systems with continuous states one has to deal with the fact that their values will depend on the resolution with which the systems states are observed. For deterministic systems both measures will diverge with increasing resolution. We therefore propose a new decomposition of the excess entropy in resolution dependent and resolution independent parts and discuss how they depend on the dimensionality of the dynamics, correlations and the noise level. For the practical estimation we propose to use estimates based on the correlation integral instead of the direct estimation of the mutual information using the algorithm by Kraskov et al. (2004) which is based on next neighbor statistics because the latter allows less control of the scale dependencies. Using our algorithm we are able to show how autonomous learning generates behavior of increasing complexity with increasing learning duration.
* 24 pages, 10 figures, submitted Entropy Journal