Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Stochastic Gradient Descent for Distributionally Robust Learning
May 22, 2018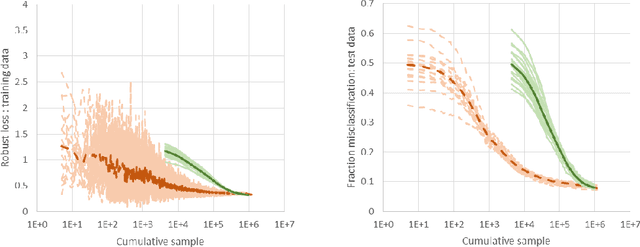
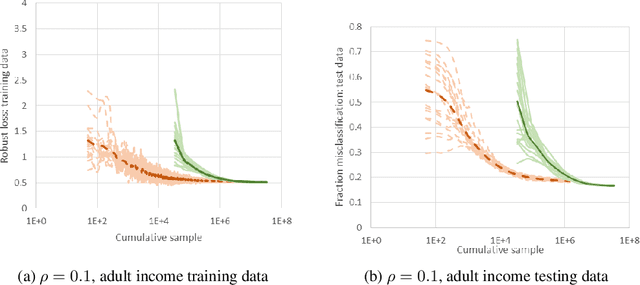
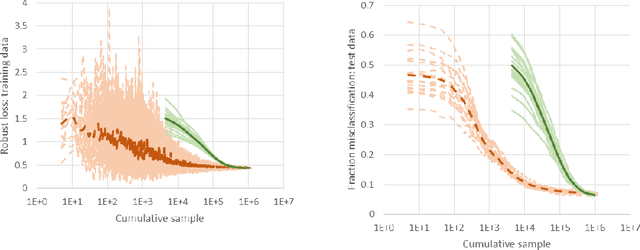
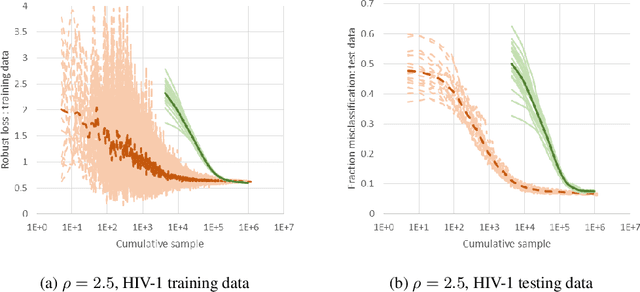
We consider a new stochastic gradient descent algorithm for efficiently solving general min-max optimization problems that arise naturally in distributionally robust learning. By focusing on the entire dataset, current approaches do not scale well. We address this issue by initially focusing on a subset of the data and progressively increasing this support to statistically cover the entire dataset.
* 19 Pages, NIPS 2018 submission
Via