 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEthnicity sensitive author disambiguation using semi-supervised learning
May 04, 2016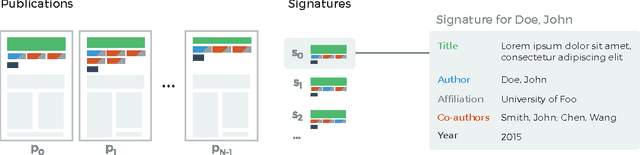

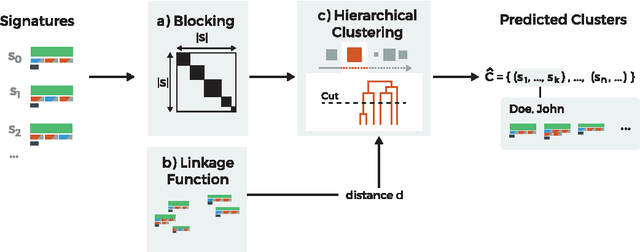

Author name disambiguation in bibliographic databases is the problem of grouping together scientific publications written by the same person, accounting for potential homonyms and/or synonyms. Among solutions to this problem, digital libraries are increasingly offering tools for authors to manually curate their publications and claim those that are theirs. Indirectly, these tools allow for the inexpensive collection of large annotated training data, which can be further leveraged to build a complementary automated disambiguation system capable of inferring patterns for identifying publications written by the same person. Building on more than 1 million publicly released crowdsourced annotations, we propose an automated author disambiguation solution exploiting this data (i) to learn an accurate classifier for identifying coreferring authors and (ii) to guide the clustering of scientific publications by distinct authors in a semi-supervised way. To the best of our knowledge, our analysis is the first to be carried out on data of this size and coverage. With respect to the state of the art, we validate the general pipeline used in most existing solutions, and improve by: (i) proposing phonetic-based blocking strategies, thereby increasing recall; and (ii) adding strong ethnicity-sensitive features for learning a linkage function, thereby tailoring disambiguation to non-Western author names whenever necessary.