 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCERN for AGI: A Theoretical Framework for Autonomous Simulation-Based Artificial Intelligence Testing and Alignment
Dec 14, 2023This paper explores the potential of a multidisciplinary approach to testing and aligning artificial general intelligence (AGI) and LLMs. Due to the rapid development and wide application of LLMs, challenges such as ethical alignment, controllability, and predictability of these models have become important research topics. This study investigates an innovative simulation-based multi-agent system within a virtual reality framework that replicates the real-world environment. The framework is populated by automated 'digital citizens,' simulating complex social structures and interactions to examine and optimize AGI. Application of various theories from the fields of sociology, social psychology, computer science, physics, biology, and economics demonstrates the possibility of a more human-aligned and socially responsible AGI. The purpose of such a digital environment is to provide a dynamic platform where advanced AI agents can interact and make independent decisions, thereby mimicking realistic scenarios. The actors in this digital city, operated by the LLMs, serve as the primary agents, exhibiting high degrees of autonomy. While this approach shows immense potential, there are notable challenges and limitations, most significantly the unpredictable nature of real-world social dynamics. This research endeavors to contribute to the development and refinement of AGI, emphasizing the integration of social, ethical, and theoretical dimensions for future research.
Identifying Individual Dogs in Social Media Images
Mar 14, 2020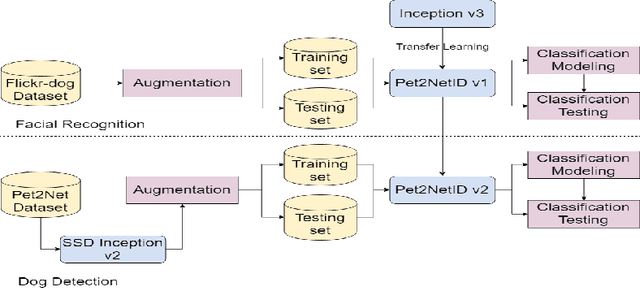

We present the results of an initial study focused on developing a visual AI solution able to recognize individual dogs in unconstrained (wild) images occurring on social media. The work described here is part of joint project done with Pet2Net, a social network focused on pets and their owners. In order to detect and recognize individual dogs we combine transfer learning and object detection approaches on Inception v3 and SSD Inception v2 architectures respectively and evaluate the proposed pipeline using a new data set containing real data that the users uploaded to Pet2Net platform. We show that it can achieve 94.59% accuracy in identifying individual dogs. Our approach has been designed with simplicity in mind and the goal of easy deployment on all the images uploaded to Pet2Net platform. A purely visual approach to identifying dogs in images, will enhance Pet2Net features aimed at finding lost dogs, as well as form the basis of future work focused on identifying social relationships between dogs, which cannot be inferred from other data collected by the platform.
Self Paced Deep Learning for Weakly Supervised Object Detection
Feb 21, 2018

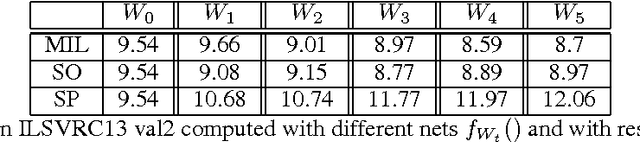

In a weakly-supervised scenario object detectors need to be trained using image-level annotation alone. Since bounding-box-level ground truth is not available, most of the solutions proposed so far are based on an iterative, Multiple Instance Learning framework in which the current classifier is used to select the highest-confidence boxes in each image, which are treated as pseudo-ground truth in the next training iteration. However, the errors of an immature classifier can make the process drift, usually introducing many of false positives in the training dataset. To alleviate this problem, we propose in this paper a training protocol based on the self-paced learning paradigm. The main idea is to iteratively select a subset of images and boxes that are the most reliable, and use them for training. While in the past few years similar strategies have been adopted for SVMs and other classifiers, we are the first showing that a self-paced approach can be used with deep-network-based classifiers in an end-to-end training pipeline. The method we propose is built on the fully-supervised Fast-RCNN architecture and can be applied to similar architectures which represent the input image as a bag of boxes. We show state-of-the-art results on Pascal VOC 2007, Pascal VOC 2010 and ILSVRC 2013. On ILSVRC 2013 our results based on a low-capacity AlexNet network outperform even those weakly-supervised approaches which are based on much higher-capacity networks.