 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Meta-learning for Tabular Prediction Tasks with Adversarially Pre-trained Transformer
Feb 06, 2025



We present an Adversarially Pre-trained Transformer (APT) that is able to perform zero-shot meta-learning on tabular prediction tasks without pre-training on any real-world dataset, extending on the recent development of Prior-Data Fitted Networks (PFNs) and TabPFN. Specifically, APT is pre-trained with adversarial synthetic data agents, who continue to shift their underlying data generating distribution and deliberately challenge the model with different synthetic datasets. In addition, we propose a mixture block architecture that is able to handle classification tasks with arbitrary number of classes, addressing the class size limitation -- a crucial weakness of prior deep tabular zero-shot learners. In experiments, we show that our framework matches state-of-the-art performance on small classification tasks without filtering on dataset characteristics such as number of classes and number of missing values, while maintaining an average runtime under one second. On common benchmark dataset suites in both classification and regression, we show that adversarial pre-training was able to enhance TabPFN's performance. In our analysis, we demonstrate that the adversarial synthetic data agents were able to generate a more diverse collection of data compared to the ordinary random generator in TabPFN. In addition, we demonstrate that our mixture block neural design has improved generalizability and greatly accelerated pre-training.
Symmetry constrained machine learning
Nov 16, 2018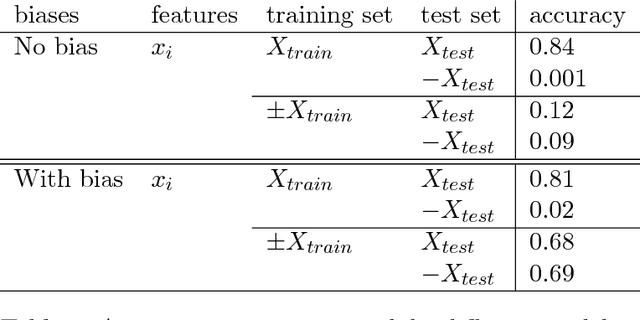


Symmetry, a central concept in understanding the laws of nature, has been used for centuries in physics, mathematics, and chemistry, to help make mathematical models tractable. Yet, despite its power, symmetry has not been used extensively in machine learning, until rather recently. In this article we show a general way to incorporate symmetries into machine learning models. We demonstrate this with a detailed analysis on a rather simple real world machine learning system - a neural network for classifying handwritten digits, lacking bias terms for every neuron. We demonstrate that ignoring symmetries can have dire over-fitting consequences, and that incorporating symmetry into the model reduces over-fitting, while at the same time reducing complexity, ultimately requiring less training data, and taking less time and resources to train.