 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTadML: A fast temporal action detection with Mechanics-MLP
Jun 07, 2022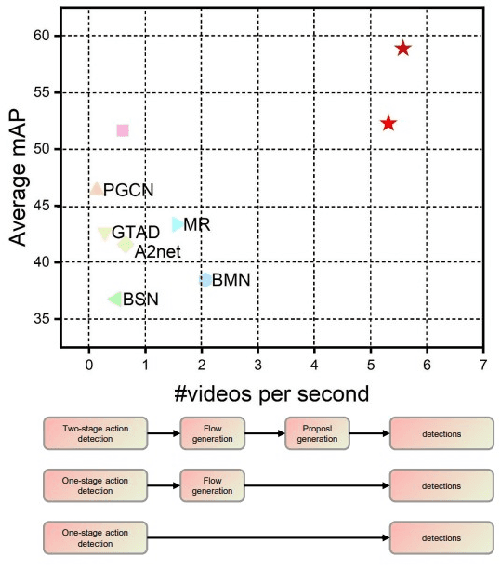

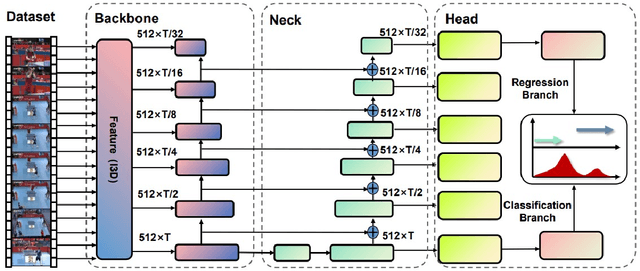

Temporal Action Detection(TAD) is a crucial but challenging task in video understanding.It is aimed at detecting both the type and start-end frame for each action instance in a long, untrimmed video.Most current models adopt both RGB and Optical-Flow streams for the TAD task. Thus, original RGB frames must be converted manually into Optical-Flow frames with additional computation and time cost, which is an obstacle to achieve real-time processing. At present, many models adopt two-stage strategies, which would slow the inference speed down and complicatedly tuning on proposals generating.By comparison, we propose a one-stage anchor-free temporal localization method with RGB stream only, in which a novel Newtonian \emph{Mechanics-MLP} architecture is established. It has comparable accuracy with all existing state-of-the-art models, while surpasses the inference speed of these methods by a large margin. The typical inference speed in this paper is astounding 4.44 video per second on THUMOS14. In applications, because there is no need to convert optical flow, the inference speed will be faster.It also proves that \emph{MLP} has great potential in downstream tasks such as TAD. The source code is available at \url{https://github.com/BonedDeng/TadML}