 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeclcNet: Improving the Efficiency of Convolutional Neural Network using Channel Local Convolutions
Mar 25, 2018



Depthwise convolution and grouped convolution has been successfully applied to improve the efficiency of convolutional neural network (CNN). We suggest that these models can be considered as special cases of a generalized convolution operation, named channel local convolution(CLC), where an output channel is computed using a subset of the input channels. This definition entails computation dependency relations between input and output channels, which can be represented by a channel dependency graph(CDG). By modifying the CDG of grouped convolution, a new CLC kernel named interlaced grouped convolution (IGC) is created. Stacking IGC and GC kernels results in a convolution block (named CLC Block) for approximating regular convolution. By resorting to the CDG as an analysis tool, we derive the rule for setting the meta-parameters of IGC and GC and the framework for minimizing the computational cost. A new CNN model named clcNet is then constructed using CLC blocks, which shows significantly higher computational efficiency and fewer parameters compared to state-of-the-art networks, when being tested using the ImageNet-1K dataset. Source code is available at https://github.com/dqzhang17/clcnet.torch .
Image Recognition Using Scale Recurrent Neural Networks
Mar 25, 2018



Convolutional Neural Network(CNN) has been widely used for image recognition with great success. However, there are a number of limitations of the current CNN based image recognition paradigm. First, the receptive field of CNN is generally fixed, which limits its recognition capacity when the input image is very large. Second, it lacks the computational scalability for dealing with images with different sizes. Third, it is quite different from human visual system for image recognition, which involves both feadforward and recurrent proprocessing. This paper proposes a different paradigm of image recognition, which can take advantages of variable scales of the input images, has more computational scalabilities, and is more similar to image recognition by human visual system. It is based on recurrent neural network (RNN) defined on image scale with an embeded base CNN, which is named Scale Recurrent Neural Network(SRNN). This RNN based approach makes it easier to deal with images with variable sizes, and allows us to borrow existing RNN techniques, such as LSTM and GRU, to further enhance the recognition accuracy. Our experiments show that the recognition accuracy of a base CNN can be significantly boosted using the proposed SRNN models. It also significantly outperforms the scale ensemble method, which integrate the results of performing CNN to the input image at different scales, although the computational overhead of using SRNN is negligible.
Context-Aware Single-Shot Detector
Mar 24, 2018

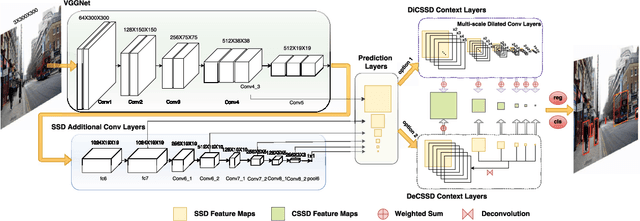
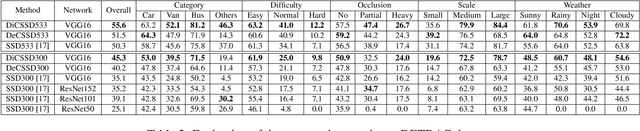
SSD is one of the state-of-the-art object detection algorithms, and it combines high detection accuracy with real-time speed. However, it is widely recognized that SSD is less accurate in detecting small objects compared to large objects, because it ignores the context from outside the proposal boxes. In this paper, we present CSSD--a shorthand for context-aware single-shot multibox object detector. CSSD is built on top of SSD, with additional layers modeling multi-scale contexts. We describe two variants of CSSD, which differ in their context layers, using dilated convolution layers (DiCSSD) and deconvolution layers (DeCSSD) respectively. The experimental results show that the multi-scale context modeling significantly improves the detection accuracy. In addition, we study the relationship between effective receptive fields (ERFs) and the theoretical receptive fields (TRFs), particularly on a VGGNet. The empirical results further strengthen our conclusion that SSD coupled with context layers achieves better detection results especially for small objects ($+3.2\% {\rm AP}_{@0.5}$ on MS-COCO compared to the newest SSD), while maintaining comparable runtime performance.