 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAda-Net: A Self-Supervised Adaptive Stereo Estimation CNN For Remote Sensing Image Data
Oct 17, 2024Stereo estimation has made many advancements in recent years with the introduction of deep-learning. However the traditional supervised approach to deep-learning requires the creation of accurate and plentiful ground-truth data, which is expensive to create and not available in many situations. This is especially true for remote sensing applications, where there is an excess of available data without proper ground truth. To tackle this problem, we propose a self-supervised CNN with self-improving adaptive abilities. In the first iteration, the created disparity map is inaccurate and noisy. Leveraging the left-right consistency check, we get a sparse but more accurate disparity map which is used as an initial pseudo ground-truth. This pseudo ground-truth is then adapted and updated after every epoch in the training step of the network. We use the sum of inconsistent points in order to track the network convergence. The code for our method is publicly available at: https://github.com/thedodo/SAda-Net}{https://github.com/thedodo/SAda-Net
FCDSN-DC: An Accurate and Lightweight Convolutional Neural Network for Stereo Estimation with Depth Completion
Sep 14, 2022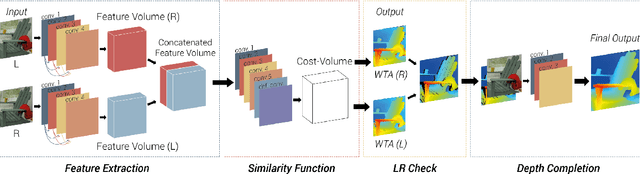
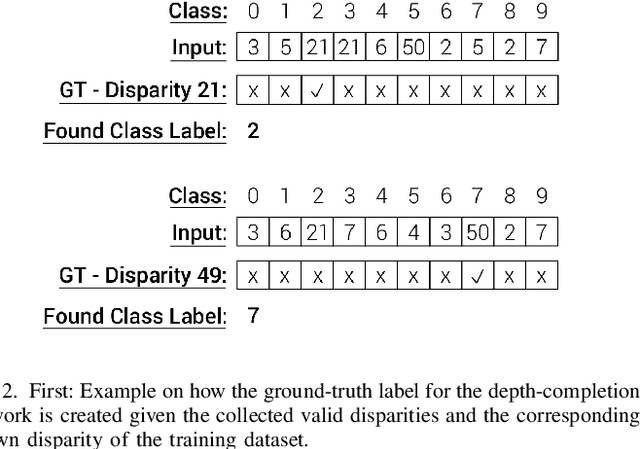

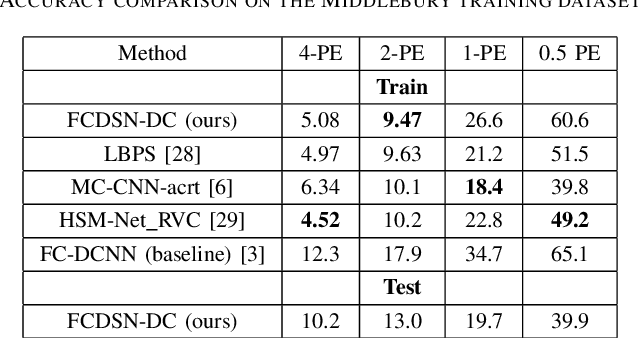
We propose an accurate and lightweight convolutional neural network for stereo estimation with depth completion. We name this method fully-convolutional deformable similarity network with depth completion (FCDSN-DC). This method extends FC-DCNN by improving the feature extractor, adding a network structure for training highly accurate similarity functions and a network structure for filling inconsistent disparity estimates. The whole method consists of three parts. The first part consists of fully-convolutional densely connected layers that computes expressive features of rectified image pairs. The second part of our network learns highly accurate similarity functions between this learned features. It consists of densely-connected convolution layers with a deformable convolution block at the end to further improve the accuracy of the results. After this step an initial disparity map is created and the left-right consistency check is performed in order to remove inconsistent points. The last part of the network then uses this input together with the corresponding left RGB image in order to train a network that fills in the missing measurements. Consistent depth estimations are gathered around invalid points and are parsed together with the RGB points into a shallow CNN network structure in order to recover the missing values. We evaluate our method on challenging real world indoor and outdoor scenes, in particular Middlebury, KITTI and ETH3D were it produces competitive results. We furthermore show that this method generalizes well and is well suited for many applications without the need of further training. The code of our full framework is available at: https://github.com/thedodo/FCDSN-DC
FC-DCNN: A densely connected neural network for stereo estimation
Oct 14, 2020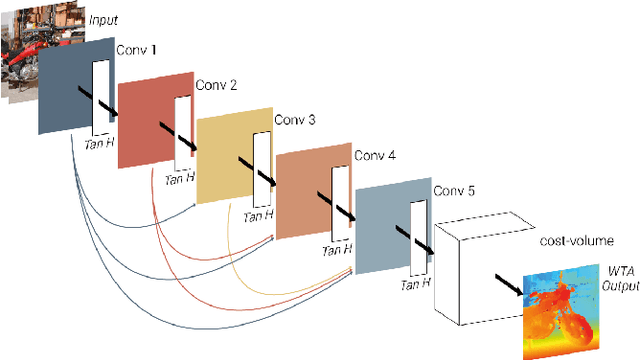


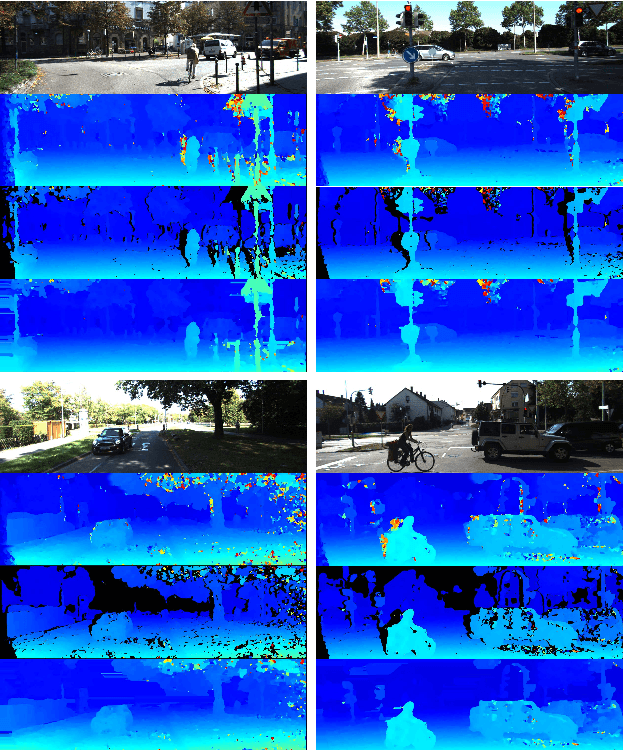
We propose a novel lightweight network for stereo estimation. Our network consists of a fully-convolutional densely connected neural network (FC-DCNN) that computes matching costs between rectified image pairs. Our FC-DCNN method learns expressive features and performs some simple but effective post-processing steps. The densely connected layer structure connects the output of each layer to the input of each subsequent layer. This network structure and the fact that we do not use any fully-connected layers or 3D convolutions leads to a very lightweight network. The output of this network is used in order to calculate matching costs and create a cost-volume. Instead of using time and memory-inefficient cost-aggregation methods such as semi-global matching or conditional random fields in order to improve the result, we rely on filtering techniques, namely median filter and guided filter. By computing a left-right consistency check we get rid of inconsistent values. Afterwards we use a watershed foreground-background segmentation on the disparity image with removed inconsistencies. This mask is then used to refine the final prediction. We show that our method works well for both challenging indoor and outdoor scenes by evaluating it on the Middlebury, KITTI and ETH3D benchmarks respectively. Our full framework is available at https://github.com/thedodo/FC-DCNN