 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Guidance Tuning for Text-To-Image Diffusion Models
Dec 26, 2023Recent advancements in Text-to-Image (T2I) diffusion models have demonstrated impressive success in generating high-quality images with zero-shot generalization capabilities. Yet, current models struggle to closely adhere to prompt semantics, often misrepresenting or overlooking specific attributes. To address this, we propose a simple, training-free approach that modulates the guidance direction of diffusion models during inference. We first decompose the prompt semantics into a set of concepts, and monitor the guidance trajectory in relation to each concept. Our key observation is that deviations in model's adherence to prompt semantics are highly correlated with divergence of the guidance from one or more of these concepts. Based on this observation, we devise a technique to steer the guidance direction towards any concept from which the model diverges. Extensive experimentation validates that our method improves the semantic alignment of images generated by diffusion models in response to prompts. Project page is available at: https://korguy.github.io/
Utilizing Task-Generic Motion Prior to Recover Full-Body Motion from Very Sparse Signals
Aug 30, 2023The most popular type of devices used to track a user's posture in a virtual reality experience consists of a head-mounted display and two controllers held in both hands. However, due to the limited number of tracking sensors (three in total), faithfully recovering the user in full-body is challenging, limiting the potential for interactions among simulated user avatars within the virtual world. Therefore, recent studies have attempted to reconstruct full-body poses using neural networks that utilize previously learned human poses or accept a series of past poses over a short period. In this paper, we propose a method that utilizes information from a neural motion prior to improve the accuracy of reconstructed user's motions. Our approach aims to reconstruct user's full-body poses by predicting the latent representation of the user's overall motion from limited input signals and integrating this information with tracking sensor inputs. This is based on the premise that the ultimate goal of pose reconstruction is to reconstruct the motion, which is a series of poses. Our results show that this integration enables more accurate reconstruction of the user's full-body motion, particularly enhancing the robustness of lower body motion reconstruction from impoverished signals. Web: https://https://mjsh34.github.io/mp-sspe/
Multi-Layered Unseen Garments Draping Network
Apr 07, 2023While recent AI-based draping networks have significantly advanced the ability to simulate the appearance of clothes worn by 3D human models, the handling of multi-layered garments remains a challenging task. This paper presents a model for draping multi-layered garments that are unseen during the training process. Our proposed framework consists of three stages: garment embedding, single-layered garment draping, and untangling. The model represents a garment independent to its topological structure by mapping it onto the $UV$ map of a human body model, allowing for the ability to handle previously unseen garments. In the single-layered garment draping phase, the model sequentially drapes all garments in each layer on the body without considering interactions between them. The untangling phase utilizes a GNN-based network to model the interaction between the garments of different layers, enabling the simulation of complex multi-layered clothing. The proposed model demonstrates strong performance on both unseen synthetic and real garment reconstruction data on a diverse range of human body shapes and poses.
Discovering Latent Representations of Relations for Interacting Systems
Nov 10, 2021
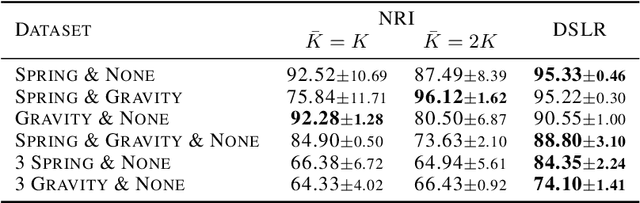

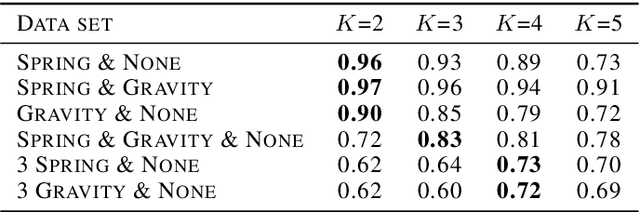
Systems whose entities interact with each other are common. In many interacting systems, it is difficult to observe the relations between entities which is the key information for analyzing the system. In recent years, there has been increasing interest in discovering the relationships between entities using graph neural networks. However, existing approaches are difficult to apply if the number of relations is unknown or if the relations are complex. We propose the DiScovering Latent Relation (DSLR) model, which is flexibly applicable even if the number of relations is unknown or many types of relations exist. The flexibility of our DSLR model comes from the design concept of our encoder that represents the relation between entities in a latent space rather than a discrete variable and a decoder that can handle many types of relations. We performed the experiments on synthetic and real-world graph data with various relationships between entities, and compared the qualitative and quantitative results with other approaches. The experiments show that the proposed method is suitable for analyzing dynamic graphs with an unknown number of complex relations.