 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-order Parameter-free Optimization for LMO-based Methods: Novel Approach for Efficient Fine-tuning
Jun 12, 2026Fine-tuning large language models (LLMs) has become a central application of modern optimization, enabling pretrained models to adapt to diverse downstream tasks and domain-specific data. A major obstacle in large-scale fine-tuning is the memory overhead of backpropagation, which requires storing activations, gradients, and optimizer states. Zeroth-order (ZO) optimization offers a memory-efficient alternative, but its performance is highly sensitive to the stepsize and smoothing parameter, often requiring costly task-specific tuning. Parameter-free (PF) optimization addresses this issue by adapting algorithmic parameters without prior knowledge of problem-dependent constants. Moreover, large-scale fine-tuning can benefit from geometry-aware updates that account for the heterogeneous structure of parameter blocks, which can be modeled through methods that exploit linear minimization oracle (LMO). In this work, we study PF adaptation for LMO-based ZO optimization and introduce $\texttt{AdaNAGED}$, a method that unifies gradient-free training, adaptive tuning, and non-Euclidean update geometry. We establish convergence guarantees and validate the method on large-scale LLM fine-tuning task with $\texttt{OPT}-1.3\mathrm{B}$ model.
Accelerated Methods with Complexity Separation Under Data Similarity for Federated Learning Problems
Jan 13, 2026Heterogeneity within data distribution poses a challenge in many modern federated learning tasks. We formalize it as an optimization problem involving a computationally heavy composite under data similarity. By employing different sets of assumptions, we present several approaches to develop communication-efficient methods. An optimal algorithm is proposed for the convex case. The constructed theory is validated through a series of experiments across various problems.
Accelerated Methods with Compressed Communications for Distributed Optimization Problems under Data Similarity
Dec 21, 2024
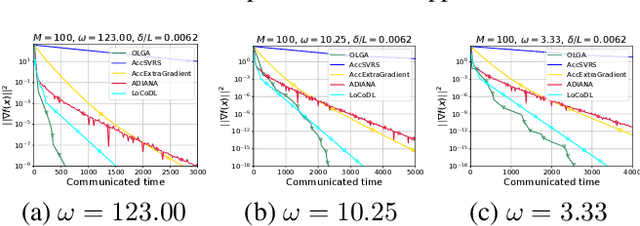


In recent years, as data and problem sizes have increased, distributed learning has become an essential tool for training high-performance models. However, the communication bottleneck, especially for high-dimensional data, is a challenge. Several techniques have been developed to overcome this problem. These include communication compression and implementation of local steps, which work particularly well when there is similarity of local data samples. In this paper, we study the synergy of these approaches for efficient distributed optimization. We propose the first theoretically grounded accelerated algorithms utilizing unbiased and biased compression under data similarity, leveraging variance reduction and error feedback frameworks. Our results are of record and confirmed by experiments on different average losses and datasets.
Accelerated Stochastic ExtraGradient: Mixing Hessian and Gradient Similarity to Reduce Communication in Distributed and Federated Learning
Sep 22, 2024Modern realities and trends in learning require more and more generalization ability of models, which leads to an increase in both models and training sample size. It is already difficult to solve such tasks in a single device mode. This is the reason why distributed and federated learning approaches are becoming more popular every day. Distributed computing involves communication between devices, which requires solving two key problems: efficiency and privacy. One of the most well-known approaches to combat communication costs is to exploit the similarity of local data. Both Hessian similarity and homogeneous gradients have been studied in the literature, but separately. In this paper, we combine both of these assumptions in analyzing a new method that incorporates the ideas of using data similarity and clients sampling. Moreover, to address privacy concerns, we apply the technique of additional noise and analyze its impact on the convergence of the proposed method. The theory is confirmed by training on real datasets.