 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLInspect: An Interactive Visual Approach to Assess Reinforcement Learning Algorithm
Nov 13, 2024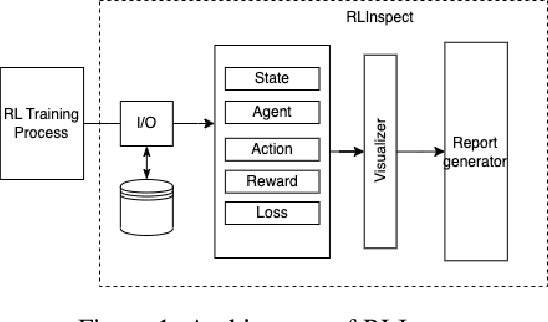
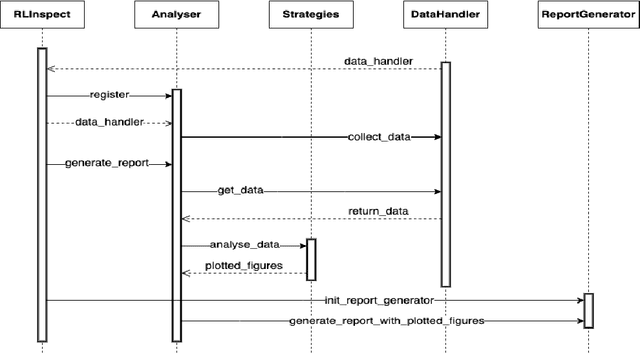
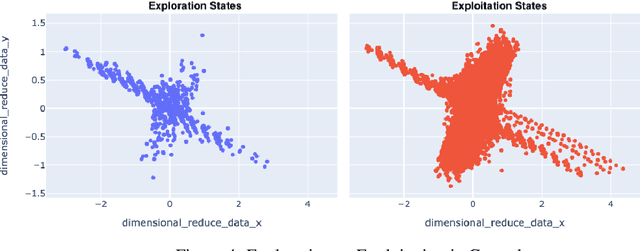
Reinforcement Learning (RL) is a rapidly growing area of machine learning that finds its application in a broad range of domains, from finance and healthcare to robotics and gaming. Compared to other machine learning techniques, RL agents learn from their own experiences using trial and error, and improve their performance over time. However, assessing RL models can be challenging, which makes it difficult to interpret their behaviour. While reward is a widely used metric to evaluate RL models, it may not always provide an accurate measure of training performance. In some cases, the reward may seem increasing while the model's performance is actually decreasing, leading to misleading conclusions about the effectiveness of the training. To overcome this limitation, we have developed RLInspect - an interactive visual analytic tool, that takes into account different components of the RL model - state, action, agent architecture and reward, and provides a more comprehensive view of the RL training. By using RLInspect, users can gain insights into the model's behaviour, identify issues during training, and potentially correct them effectively, leading to a more robust and reliable RL system.
BAMAX: Backtrack Assisted Multi-Agent Exploration using Reinforcement Learning
Nov 13, 2024Autonomous robots collaboratively exploring an unknown environment is still an open problem. The problem has its roots in coordination among non-stationary agents, each with only a partial view of information. The problem is compounded when the multiple robots must completely explore the environment. In this paper, we introduce Backtrack Assisted Multi-Agent Exploration using Reinforcement Learning (BAMAX), a method for collaborative exploration in multi-agent systems which attempts to explore an entire virtual environment. As in the name, BAMAX leverages backtrack assistance to enhance the performance of agents in exploration tasks. To evaluate BAMAX against traditional approaches, we present the results of experiments conducted across multiple hexagonal shaped grids sizes, ranging from 10x10 to 60x60. The results demonstrate that BAMAX outperforms other methods in terms of faster coverage and less backtracking across these environments.