 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards De-identification of Legal Texts
Oct 09, 2019


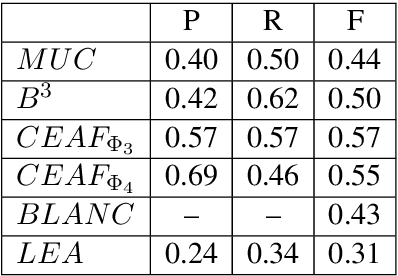
In many countries, personal information that can be published or shared between organizations is regulated and, therefore, documents must undergo a process of de-identification to eliminate or obfuscate confidential data. Our work focuses on the de-identification of legal texts, where the goal is to hide the names of the actors involved in a lawsuit without losing the sense of the story. We present a first evaluation on our corpus of NLP tools in tasks such as segmentation, tokenization and recognition of named entities, and we analyze several evaluation measures for our de-identification task. Results are meager: 84% of the documents have at least one name not covered by NER tools, something that might lead to the re-identification of involved names. We conclude that tools must be strongly adapted for processing texts of this particular domain.