 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpus based Enrichment of GermaNet Verb Frames
Feb 01, 2005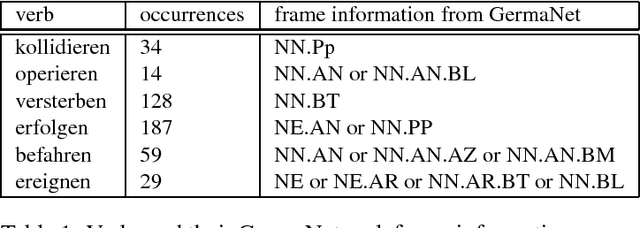

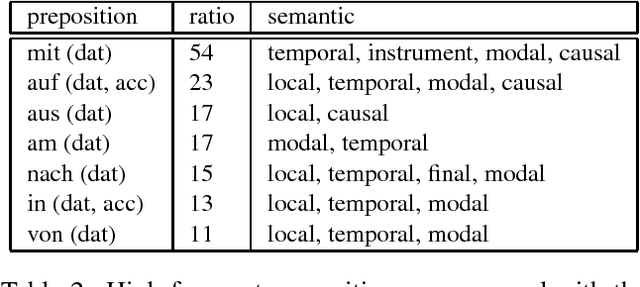
Lexical semantic resources, like WordNet, are often used in real applications of natural language document processing. For example, we integrated GermaNet in our document suite XDOC of processing of German forensic autopsy protocols. In addition to the hypernymy and synonymy relation, we want to adapt GermaNet's verb frames for our analysis. In this paper we outline an approach for the domain related enrichment of GermaNet verb frames by corpus based syntactic and co-occurred data analyses of real documents.
* 4 pages
Clever Search: A WordNet Based Wrapper for Internet Search Engines
Jan 31, 2005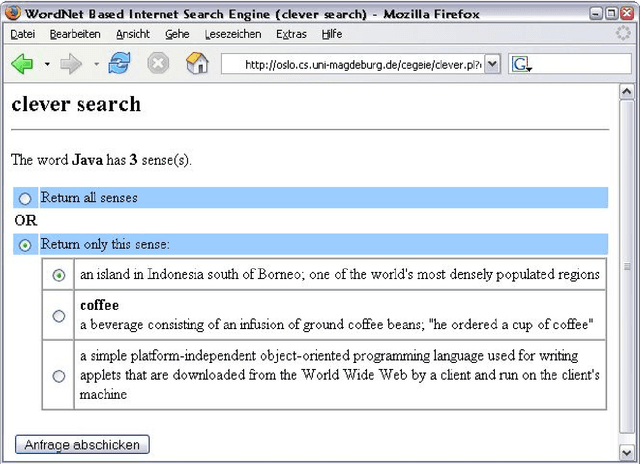
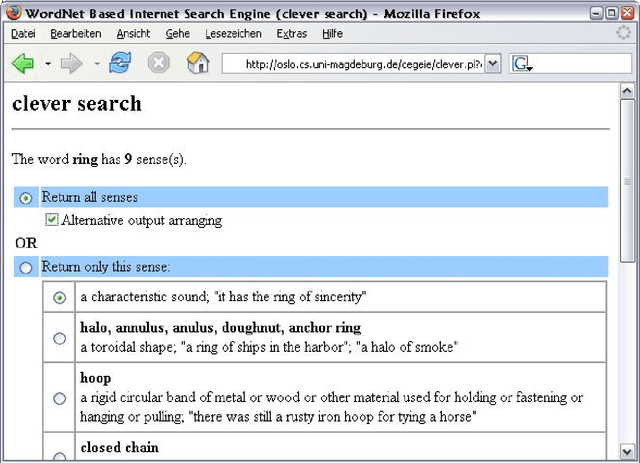
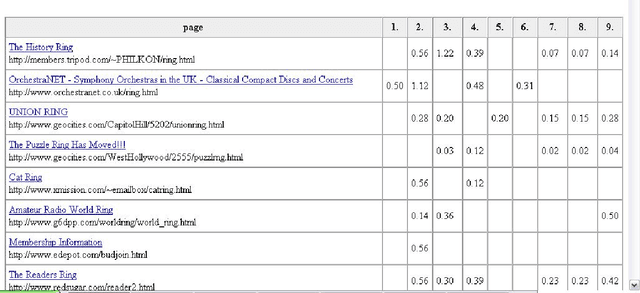
This paper presents an approach to enhance search engines with information about word senses available in WordNet. The approach exploits information about the conceptual relations within the lexical-semantic net. In the wrapper for search engines presented, WordNet information is used to specify user's request or to classify the results of a publicly available web search engine, like google, yahoo, etc.
Issues in Exploiting GermaNet as a Resource in Real Applications
Jan 31, 2005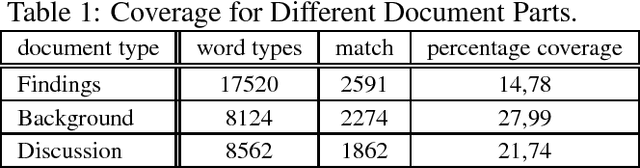
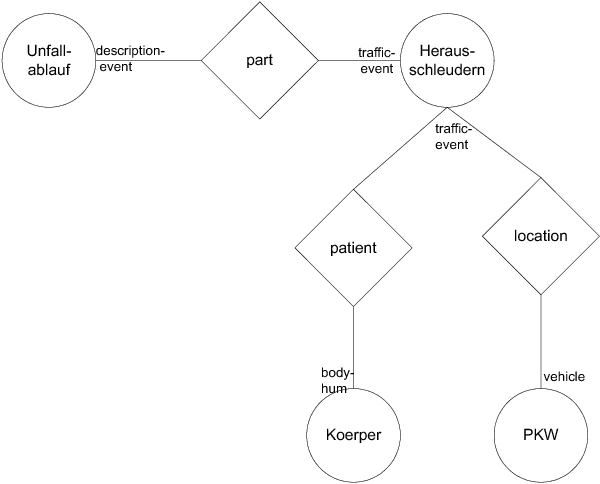
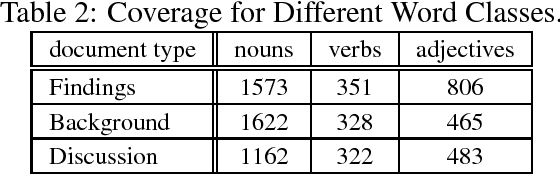
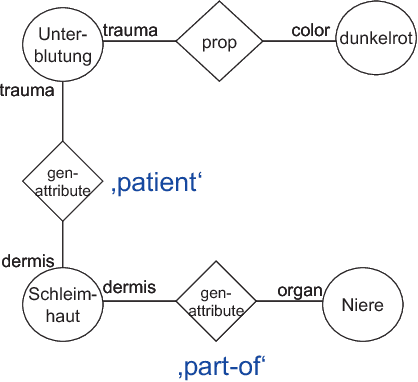
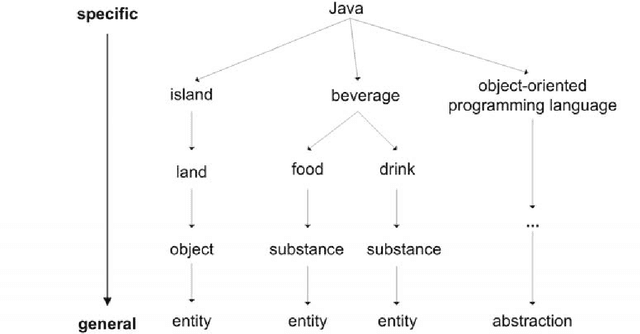
This paper reports about experiments with GermaNet as a resource within domain specific document analysis. The main question to be answered is: How is the coverage of GermaNet in a specific domain? We report about results of a field test of GermaNet for analyses of autopsy protocols and present a sketch about the integration of GermaNet inside XDOC. Our remarks will contribute to a GermaNet user's wish list.
Transforming and Enriching Documents for the Semantic Web
Jan 31, 2005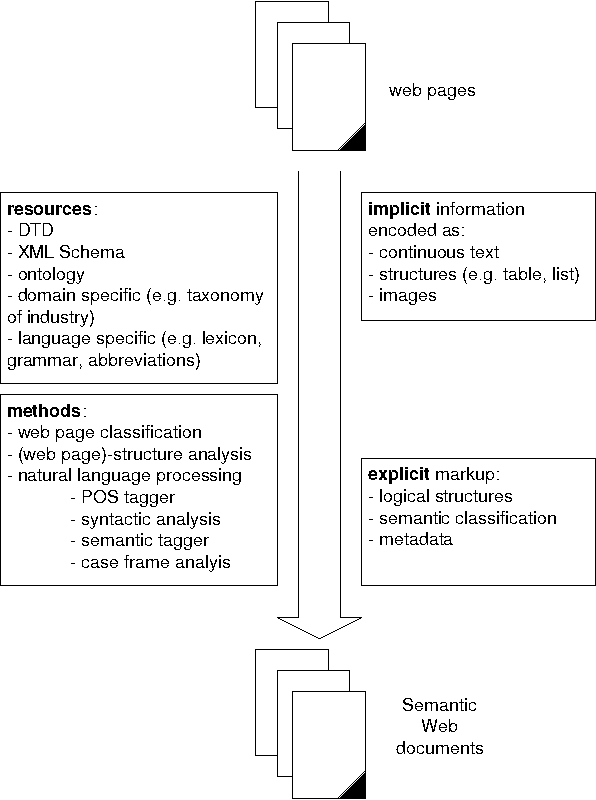
We suggest to employ techniques from Natural Language Processing (NLP) and Knowledge Representation (KR) to transform existing documents into documents amenable for the Semantic Web. Semantic Web documents have at least part of their semantics and pragmatics marked up explicitly in both a machine processable as well as human readable manner. XML and its related standards (XSLT, RDF, Topic Maps etc.) are the unifying platform for the tools and methodologies developed for different application scenarios.
* 10 pages, 1 figure
Context Related Derivation of Word Senses
Jan 31, 2005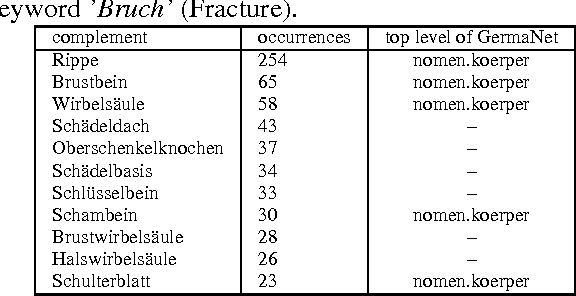
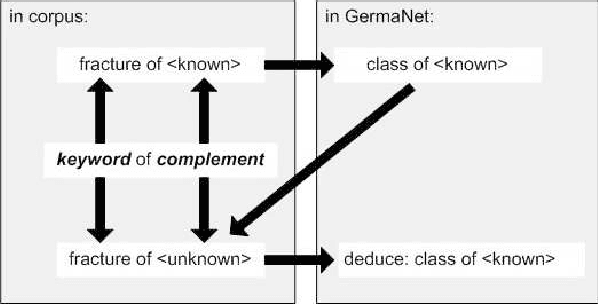

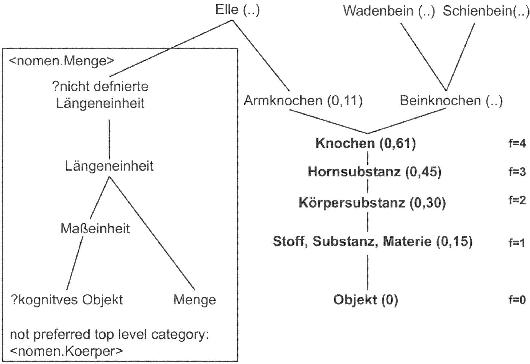
Real applications of natural language document processing are very often confronted with domain specific lexical gaps during the analysis of documents of a new domain. This paper describes an approach for the derivation of domain specific concepts for the extension of an existing ontology. As resources we need an initial ontology and a partially processed corpus of a domain. We exploit the specific characteristic of the sublanguage in the corpus. Our approach is based on syntactical structures (noun phrases) and compound analyses to extract information required for the extension of GermaNet's lexical resources.
* 5 pages, 2 figures
Transforming Business Rules Into Natural Language Text
Jan 31, 2005The aim of the project presented in this paper is to design a system for an NLG architecture, which supports the documentation process of eBusiness models. A major task is to enrich the formal description of an eBusiness model with additional information needed in an NLG task.
* 3 pages
Exploiting Sublanguage and Domain Characteristics in a Bootstrapping Approach to Lexicon and Ontology Creation
Apr 23, 2003It is very costly to build up lexical resources and domain ontologies. Especially when confronted with a new application domain lexical gaps and a poor coverage of domain concepts are a problem for the successful exploitation of natural language document analysis systems that need and exploit such knowledge sources. In this paper we report about ongoing experiments with `bootstrapping techniques' for lexicon and ontology creation.
An XML based Document Suite
Apr 22, 2003We report about the current state of development of a document suite and its applications. This collection of tools for the flexible and robust processing of documents in German is based on the use of XML as unifying formalism for encoding input and output data as well as process information. It is organized in modules with limited responsibilities that can easily be combined into pipelines to solve complex tasks. Strong emphasis is laid on a number of techniques to deal with lexical and conceptual gaps that are typical when starting a new application.