Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Related Derivation of Word Senses
Paper and Code
Jan 31, 2005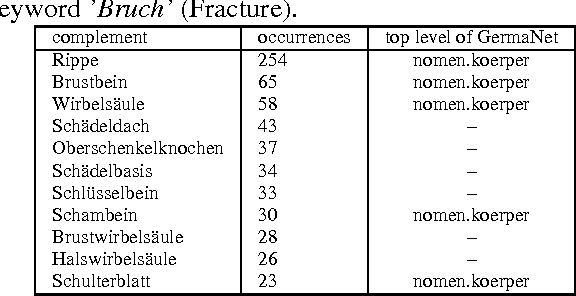
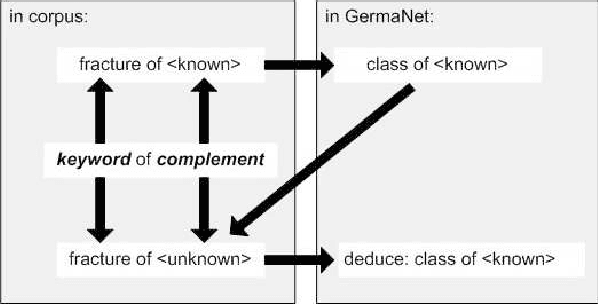

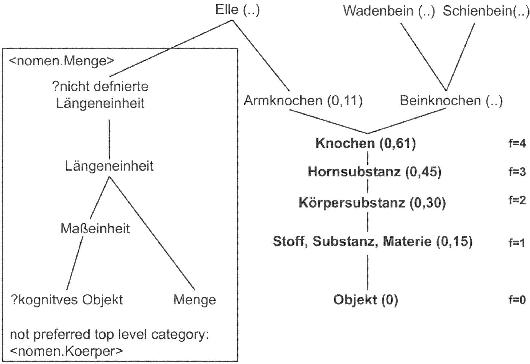
Real applications of natural language document processing are very often confronted with domain specific lexical gaps during the analysis of documents of a new domain. This paper describes an approach for the derivation of domain specific concepts for the extension of an existing ontology. As resources we need an initial ontology and a partially processed corpus of a domain. We exploit the specific characteristic of the sublanguage in the corpus. Our approach is based on syntactical structures (noun phrases) and compound analyses to extract information required for the extension of GermaNet's lexical resources.
* in Proceedings of Ontolex- Workshop 2004 * 5 pages, 2 figures
View paper on