 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViVa-SAFELAND: a New Freeware for Safe Validation of Vision-based Navigation in Aerial Vehicles
Mar 18, 2025ViVa-SAFELAND is an open source software library, aimed to test and evaluate vision-based navigation strategies for aerial vehicles, with special interest in autonomous landing, while complying with legal regulations and people's safety. It consists of a collection of high definition aerial videos, focusing on real unstructured urban scenarios, recording moving obstacles of interest, such as cars and people. Then, an Emulated Aerial Vehicle (EAV) with a virtual moving camera is implemented in order to ``navigate" inside the video, according to high-order commands. ViVa-SAFELAND provides a new, safe, simple and fair comparison baseline to evaluate and compare different visual navigation solutions under the same conditions, and to randomize variables along several trials. It also facilitates the development of autonomous landing and navigation strategies, as well as the generation of image datasets for different training tasks. Moreover, it is useful for training either human of autonomous pilots using deep learning. The effectiveness of the framework for validating vision algorithms is demonstrated through two case studies, detection of moving objects and risk assessment segmentation. To our knowledge, this is the first safe validation framework of its kind, to test and compare visual navigation solution for aerial vehicles, which is a crucial aspect for urban deployment in complex real scenarios.
Risk Assessment for Autonomous Landing in Urban Environments using Semantic Segmentation
Oct 16, 2024In this paper, we address the vision-based autonomous landing problem in complex urban environments using deep neural networks for semantic segmentation and risk assessment. We propose employing the SegFormer, a state-of-the-art visual transformer network, for the semantic segmentation of complex, unstructured urban environments. This approach yields valuable information that can be utilized in smart autonomous landing missions, particularly in emergency landing scenarios resulting from system failures or human errors. The assessment is done in real-time flight, when images of an RGB camera at the Unmanned Aerial Vehicle (UAV) are segmented with the SegFormer into the most common classes found in urban environments. These classes are then mapped into a level of risk, considering in general, potential material damage, damaging the drone itself and endanger people. The proposed strategy is validated through several case studies, demonstrating the huge potential of semantic segmentation-based strategies to determining the safest landing areas for autonomous emergency landing, which we believe will help unleash the full potential of UAVs on civil applications within urban areas.
Monitoring Social-distance in Wide Areas during Pandemics: a Density Map and Segmentation Approach
Apr 07, 2021



With the relaxation of the containment measurements around the globe, monitoring the social distancing in crowded public places is of grate importance to prevent a new massive wave of COVID-19 infections. Recent works in that matter have limited themselves by detecting social distancing in corridors up to small crowds by detecting each person individually considering the full body in the image. In this work, we propose a new framework for monitoring the social-distance using end-to-end Deep Learning, to detect crowds violating the social-distance in wide areas where important occlusions may be present. Our framework consists in the creation of a new ground truth based on the ground truth density maps and the proposal of two different solutions, a density-map-based and a segmentation-based, to detect the crowds violating the social-distance constrain. We assess the results of both approaches by using the generated ground truth from the PET2009 and CityStreet datasets. We show that our framework performs well at providing the zones where people are not following the social-distance even when heavily occluded or far away from one camera.
Vibration Analysis in Bearings for Failure Prevention using CNN
May 06, 2020
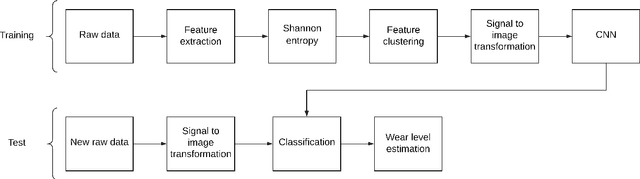


Timely failure detection for bearings is of great importance to prevent economic loses in the industry. In this article we propose a method based on Convolutional Neural Networks (CNN) to estimate the level of wear in bearings. First of all, an automatic labeling of the raw vibration data is performed to obtain different levels of bearing wear, by means of the Root Mean Square features along with the Shannon's entropy to extract features from the raw data, which is then grouped in seven different classes using the K-means algorithm to obtain the labels. Then, the raw vibration data is converted into small square images, each sample of the data representing one pixel of the image. Following this, we propose a CNN model based on the AlexNet architecture to classify the wear level and diagnose the rotatory system. To train the network and validate our proposal, we use a dataset from the center of Intelligent Maintenance Systems (IMS), and extensively compare it with other methods reported in the literature. The effectiveness of the proposed strategy proved to be excellent, outperforming other approaches in the state-of-the-art.
On the safety of vulnerable road users by cyclist orientation detection using Deep Learning
Apr 25, 2020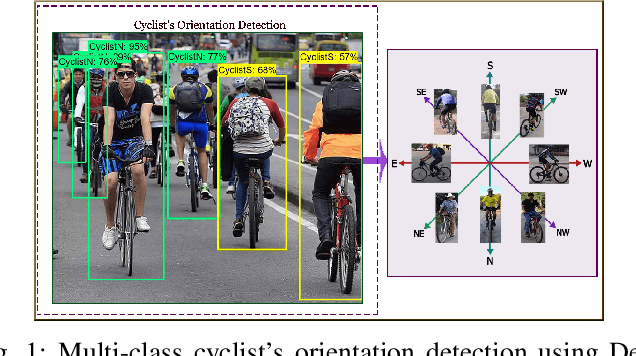

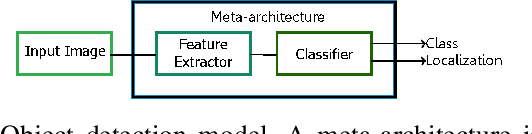
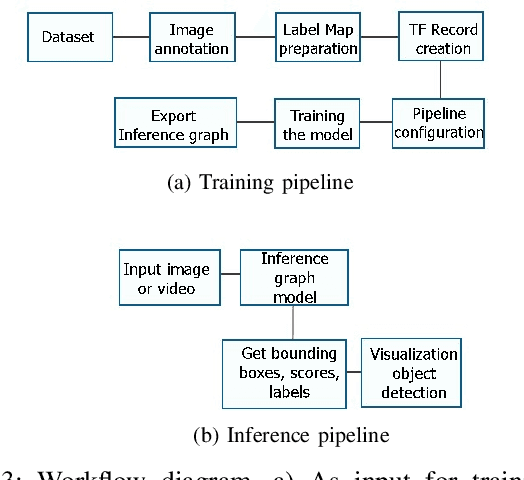
In this work, orientation detection using Deep Learning is acknowledged for a particularly vulnerable class of road users,the cyclists. Knowing the cyclists' orientation is of great relevance since it provides a good notion about their future trajectory, which is crucial to avoid accidents in the context of intelligent transportation systems. Using Transfer Learning with pre-trained models and TensorFlow, we present a performance comparison between the main algorithms reported in the literature for object detection,such as SSD, Faster R-CNN and R-FCN along with MobilenetV2, InceptionV2, ResNet50, ResNet101 feature extractors. Moreover, we propose multi-class detection with eight different classes according to orientations. To do so, we introduce a new dataset called "Detect-Bike", containing 20,229 cyclist instances over 11,103 images, which has been labeled based on cyclist's orientation. Then, the same Deep Learning methods used for detection are trained to determine the target's heading. Our experimental results and vast evaluation showed satisfactory performance of all of the studied methods for the cyclists and their orientation detection, especially using Faster R-CNN with ResNet50 proved to be precise but significantly slower. Meanwhile, SSD using InceptionV2 provided good trade-off between precision and execution time, and is to be preferred for real-time embedded applications.