Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning with Local Attention-Aware Feature
Aug 01, 2021

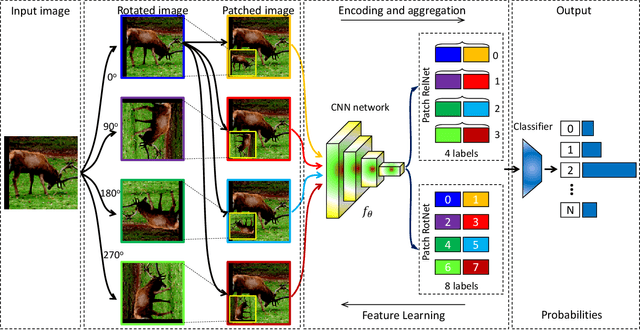

In this work, we propose a novel methodology for self-supervised learning for generating global and local attention-aware visual features. Our approach is based on training a model to differentiate between specific image transformations of an input sample and the patched images. Utilizing this approach, the proposed method is able to outperform the previous best competitor by 1.03% on the Tiny-ImageNet dataset and by 2.32% on the STL-10 dataset. Furthermore, our approach outperforms the fully-supervised learning method on the STL-10 dataset. Experimental results and visualizations show the capability of successfully learning global and local attention-aware visual representations.
* 5 pages, 4 figures
Via