 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Machine Learning to Detect Data Curation Activities
Apr 30, 2021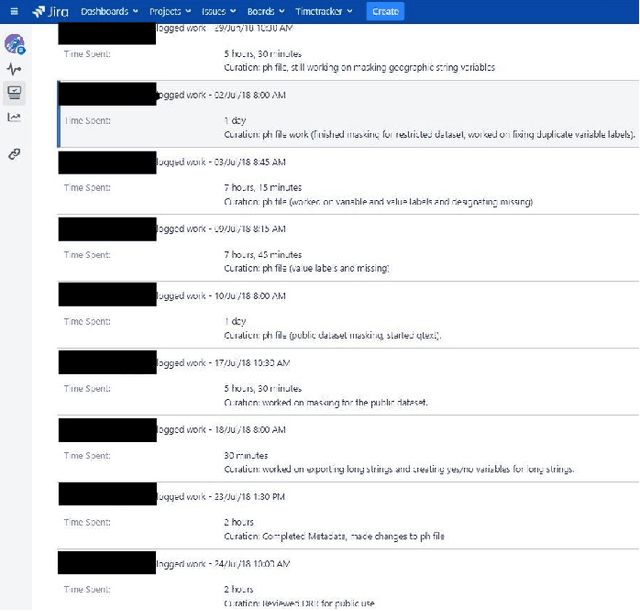
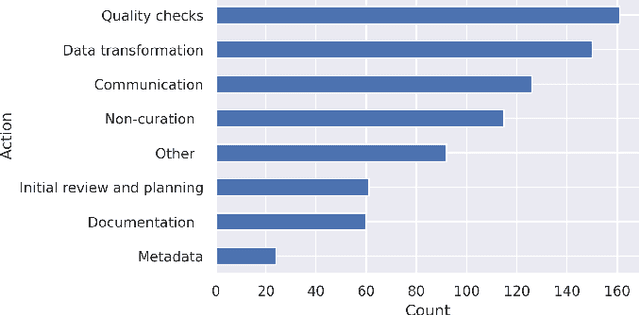
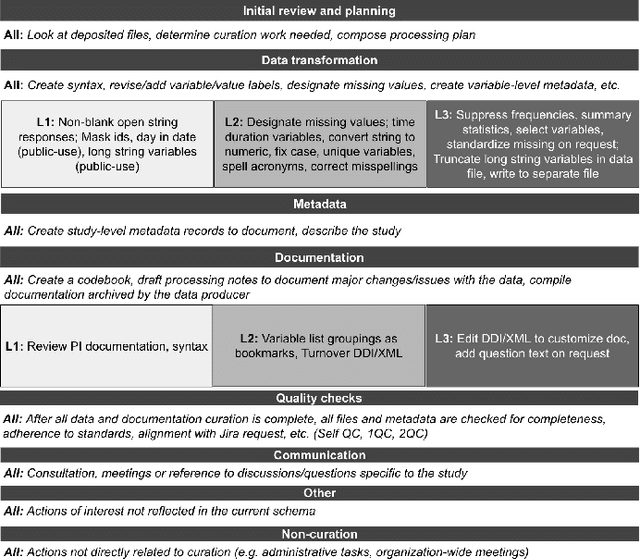
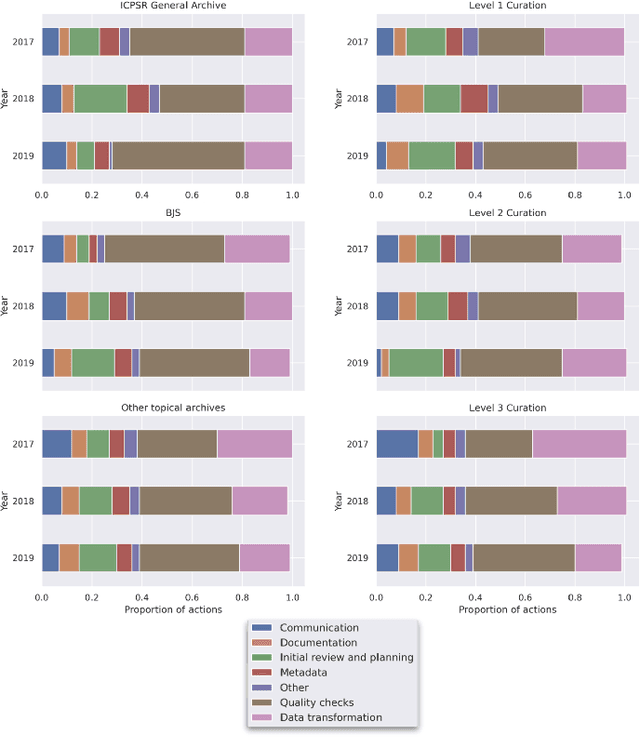
This paper describes a machine learning approach for annotating and analyzing data curation work logs at ICPSR, a large social sciences data archive. The systems we studied track curation work and coordinate team decision-making at ICPSR. Repository staff use these systems to organize, prioritize, and document curation work done on datasets, making them promising resources for studying curation work and its impact on data reuse, especially in combination with data usage analytics. A key challenge, however, is classifying similar activities so that they can be measured and associated with impact metrics. This paper contributes: 1) a schema of data curation activities; 2) a computational model for identifying curation actions in work log descriptions; and 3) an analysis of frequent data curation activities at ICPSR over time. We first propose a schema of data curation actions to help us analyze the impact of curation work. We then use this schema to annotate a set of data curation logs, which contain records of data transformations and project management decisions completed by repository staff. Finally, we train a text classifier to detect the frequency of curation actions in a large set of work logs. Our approach supports the analysis of curation work documented in work log systems as an important step toward studying the relationship between research data curation and data reuse.