 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime--to--Digital Converter (TDC)--Based Resonant Compute--in--Memory for INT8 CNNs with Layer--Optimized SRAM Mapping
Jan 01, 2026In recent years, Compute-in-memory (CiM) architectures have emerged as a promising solution for deep neural network (NN) accelerators. Multiply-accumulate~(MAC) is considered a {\textit de facto} unit operation in NNs. By leveraging the inherent parallel processing capabilities of CiM, NNs that require numerous MAC operations can be executed more efficiently. This is further facilitated by storing the weights in SRAM, reducing the need for extensive data movement and enhancing overall computational speed and efficiency. Traditional CiM architectures execute MAC operations in the analog domain, employing an Analog-to-Digital converter (ADC) to convert the analog MAC values into digital outputs. However, these ADCs introduce significant increase in area and power consumption, as well as introduce non-linearities. This work proposes a resonant time-domain compute-in-memory (TDC-CiM) architecture that eliminates the need for an ADC by using a time-to-digital converter (TDC) to digitize analog MAC results with lower power and area cost. A dedicated 8T SRAM cell enables reliable bitwise MAC operations, while the readout uses a 4-bit TDC with pulse-shrinking delay elements, achieving 1 GS/s sampling with a power consumption of only 1.25 mW. In addition, a weight stationary data mapping strategy combined with an automated SRAM macro selection algorithm enables scalable and energy-efficient deployment across CNN workloads. Evaluation across six CNN models shows that the algorithm reduces inference energy consumption by up to 8x when scaling SRAM size from 32~KB to 256~KB, while maintaining minimal accuracy loss after quantization. The feasibility of the proposed architecture is validated on an 8~KB SRAM memory array using TSMC 28~nm technology. The proposed TDC-CiM architecture demonstrates a throughput of 320~GOPS with an energy efficiency of 38.46~TOPS/W.
TSPC-PFD: TSPC-Based Low-Power High-Resolution CMOS Phase Frequency Detector
Aug 23, 2025Phase Frequency Detectors (PFDs) are essential components in Phase-Locked Loop (PLL) and Delay-Locked Loop (DLL) systems, responsible for comparing phase and frequency differences and generating up/down signals to regulate charge pumps and/or, consequently, Voltage-Controlled Oscillators (VCOs). Conventional PFD designs often suffer from significant dead zones and blind zones, which degrade phase detection accuracy and increase jitter in high-speed applications. This paper addresses PFD design challenges and presents a novel low-power True Single-Phase Clock (TSPC)-based PFD. The proposed design eliminates the blind zone entirely while achieving a minimal dead zone of 40 ps. The proposed PFD, implemented using TSMC 28 nm technology, demonstrates a low-power consumption of 4.41 uW at 3 GHz input frequency with a layout area of $10.42\mu m^2$.
EA: An Event Autoencoder for High-Speed Vision Sensing
Jul 09, 2025High-speed vision sensing is essential for real-time perception in applications such as robotics, autonomous vehicles, and industrial automation. Traditional frame-based vision systems suffer from motion blur, high latency, and redundant data processing, limiting their performance in dynamic environments. Event cameras, which capture asynchronous brightness changes at the pixel level, offer a promising alternative but pose challenges in object detection due to sparse and noisy event streams. To address this, we propose an event autoencoder architecture that efficiently compresses and reconstructs event data while preserving critical spatial and temporal features. The proposed model employs convolutional encoding and incorporates adaptive threshold selection and a lightweight classifier to enhance recognition accuracy while reducing computational complexity. Experimental results on the existing Smart Event Face Dataset (SEFD) demonstrate that our approach achieves comparable accuracy to the YOLO-v4 model while utilizing up to $35.5\times$ fewer parameters. Implementations on embedded platforms, including Raspberry Pi 4B and NVIDIA Jetson Nano, show high frame rates ranging from 8 FPS up to 44.8 FPS. The proposed classifier exhibits up to 87.84x better FPS than the state-of-the-art and significantly improves event-based vision performance, making it ideal for low-power, high-speed applications in real-time edge computing.
Descriptor: Face Detection Dataset for Programmable Threshold-Based Sparse-Vision
Oct 01, 2024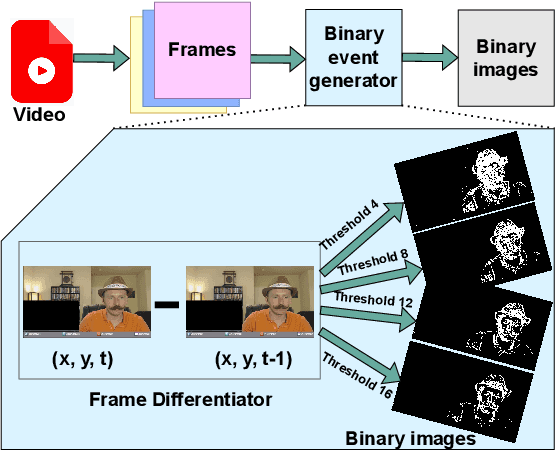
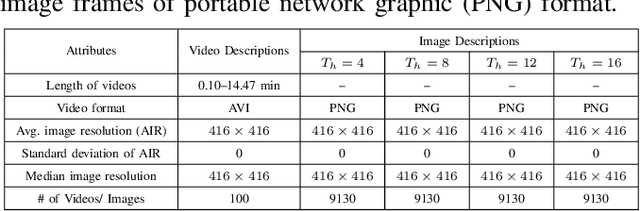
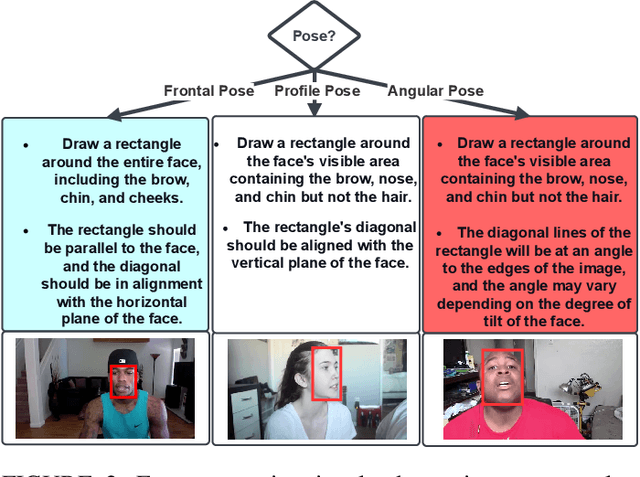

Smart focal-plane and in-chip image processing has emerged as a crucial technology for vision-enabled embedded systems with energy efficiency and privacy. However, the lack of special datasets providing examples of the data that these neuromorphic sensors compute to convey visual information has hindered the adoption of these promising technologies. Neuromorphic imager variants, including event-based sensors, produce various representations such as streams of pixel addresses representing time and locations of intensity changes in the focal plane, temporal-difference data, data sifted/thresholded by temporal differences, image data after applying spatial transformations, optical flow data, and/or statistical representations. To address the critical barrier to entry, we provide an annotated, temporal-threshold-based vision dataset specifically designed for face detection tasks derived from the same videos used for Aff-Wild2. By offering multiple threshold levels (e.g., 4, 8, 12, and 16), this dataset allows for comprehensive evaluation and optimization of state-of-the-art neural architectures under varying conditions and settings compared to traditional methods. The accompanying tool flow for generating event data from raw videos further enhances accessibility and usability. We anticipate that this resource will significantly support the development of robust vision systems based on smart sensors that can process based on temporal-difference thresholds, enabling more accurate and efficient object detection and localization and ultimately promoting the broader adoption of low-power, neuromorphic imaging technologies. To support further research, we publicly released the dataset at \url{https://dx.doi.org/10.21227/bw2e-dj78}.