 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust Through Transparency: Explainable Social Navigation for Autonomous Mobile Robots via Vision-Language Models
Apr 07, 2025

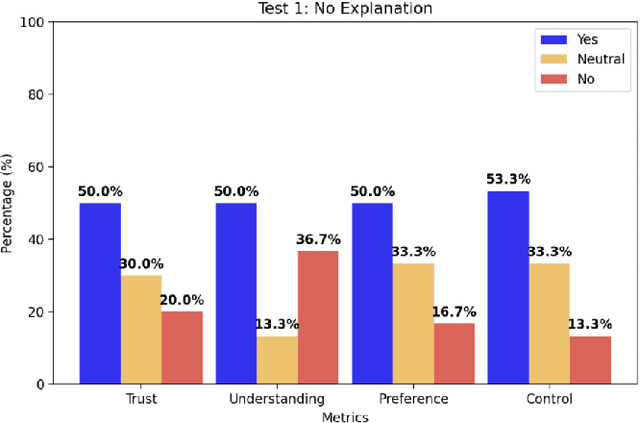

Service and assistive robots are increasingly being deployed in dynamic social environments; however, ensuring transparent and explainable interactions remains a significant challenge. This paper presents a multimodal explainability module that integrates vision language models and heat maps to improve transparency during navigation. The proposed system enables robots to perceive, analyze, and articulate their observations through natural language summaries. User studies (n=30) showed a preference of majority for real-time explanations, indicating improved trust and understanding. Our experiments were validated through confusion matrix analysis to assess the level of agreement with human expectations. Our experimental and simulation results emphasize the effectiveness of explainability in autonomous navigation, enhancing trust and interpretability.