Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear discriminant initialization for feed-forward neural networks
Aug 18, 2020
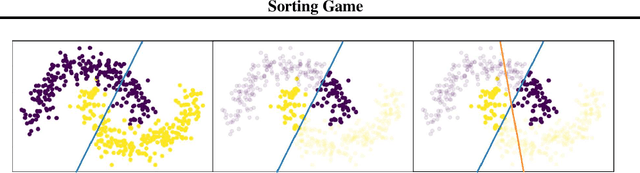
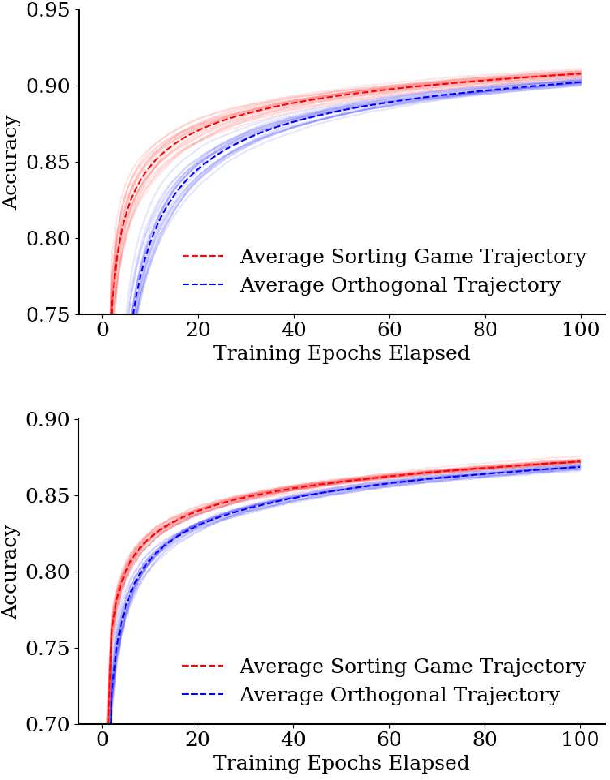

Informed by the basic geometry underlying feed forward neural networks, we initialize the weights of the first layer of a neural network using the linear discriminants which best distinguish individual classes. Networks initialized in this way take fewer training steps to reach the same level of training, and asymptotically have higher accuracy on training data.
* 6 pages, 7 figures. Added comparison to larger randomly initialized
networks. Updated tables to better illustrate trends in effect size
Via