 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReview of Case-Based Reasoning for LLM Agents: Theoretical Foundations, Architectural Components, and Cognitive Integration
Apr 09, 2025Agents powered by Large Language Models (LLMs) have recently demonstrated impressive capabilities in various tasks. Still, they face limitations in tasks requiring specific, structured knowledge, flexibility, or accountable decision-making. While agents are capable of perceiving their environments, forming inferences, planning, and executing actions towards goals, they often face issues such as hallucinations and lack of contextual memory across interactions. This paper explores how Case-Based Reasoning (CBR), a strategy that solves new problems by referencing past experiences, can be integrated into LLM agent frameworks. This integration allows LLMs to leverage explicit knowledge, enhancing their effectiveness. We systematically review the theoretical foundations of these enhanced agents, identify critical framework components, and formulate a mathematical model for the CBR processes of case retrieval, adaptation, and learning. We also evaluate CBR-enhanced agents against other methods like Chain-of-Thought reasoning and standard Retrieval-Augmented Generation, analyzing their relative strengths. Moreover, we explore how leveraging CBR's cognitive dimensions (including self-reflection, introspection, and curiosity) via goal-driven autonomy mechanisms can further enhance the LLM agent capabilities. Contributing to the ongoing research on neuro-symbolic hybrid systems, this work posits CBR as a viable technique for enhancing the reasoning skills and cognitive aspects of autonomous LLM agents.
Improving Zero-Shot Entity Retrieval through Effective Dense Representations
Mar 06, 2021
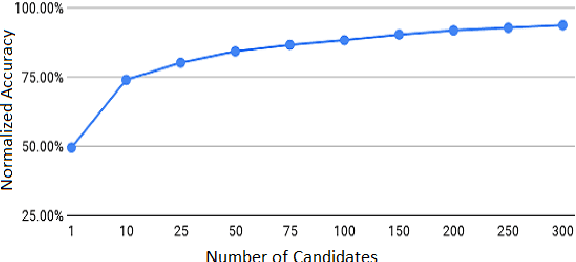

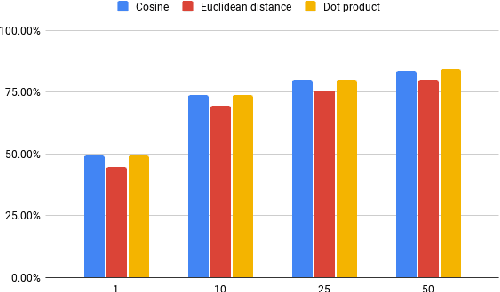
Entity Linking (EL) seeks to align entity mentions in text to entries in a knowledge-base and is usually comprised of two phases: candidate generation and candidate ranking. While most methods focus on the latter, it is the candidate generation phase that sets an upper bound to both time and accuracy performance of the overall EL system. This work's contribution is a significant improvement in candidate generation which thus raises the performance threshold for EL, by generating candidates that include the gold entity in the least candidate set (top-K). We propose a simple approach that efficiently embeds mention-entity pairs in dense space through a BERT-based bi-encoder. Specifically, we extend (Wu et al., 2020) by introducing a new pooling function and incorporating entity type side-information. We achieve a new state-of-the-art 84.28% accuracy on top-50 candidates on the Zeshel dataset, compared to the previous 82.06% on the top-64 of (Wu et al., 2020). We report the results from extensive experimentation using our proposed model on both seen and unseen entity datasets. Our results suggest that our method could be a useful complement to existing EL approaches.
Improving Distantly-Supervised Relation Extraction through BERT-based Label & Instance Embeddings
Feb 01, 2021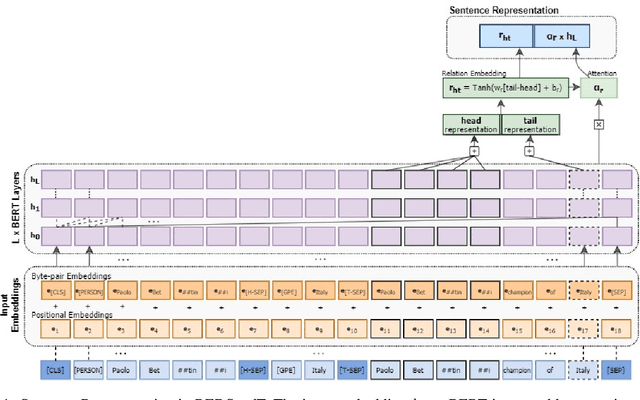
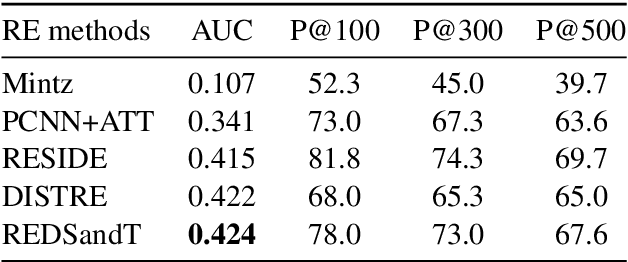
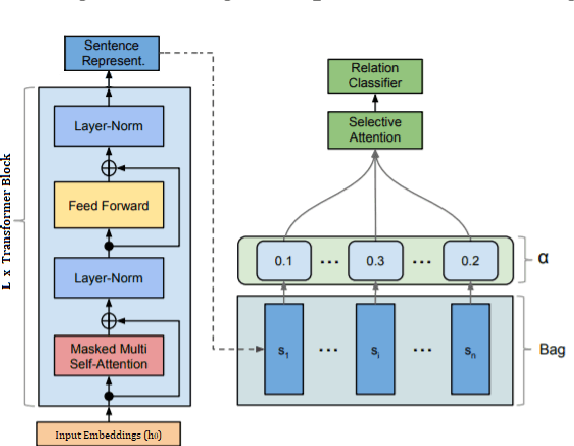

Distantly-supervised relation extraction (RE) is an effective method to scale RE to large corpora but suffers from noisy labels. Existing approaches try to alleviate noise through multi-instance learning and by providing additional information, but manage to recognize mainly the top frequent relations, neglecting those in the long-tail. We propose REDSandT (Relation Extraction with Distant Supervision and Transformers), a novel distantly-supervised transformer-based RE method, that manages to capture a wider set of relations through highly informative instance and label embeddings for RE, by exploiting BERT's pre-trained model, and the relationship between labels and entities, respectively. We guide REDSandT to focus solely on relational tokens by fine-tuning BERT on a structured input, including the sub-tree connecting an entity pair and the entities' types. Using the extracted informative vectors, we shape label embeddings, which we also use as attention mechanism over instances to further reduce noise. Finally, we represent sentences by concatenating relation and instance embeddings. Experiments in the NYT-10 dataset show that REDSandT captures a broader set of relations with higher confidence, achieving state-of-the-art AUC (0.424).