 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEACELEB: An East Asian Language Speaking Celebrity Dataset for Speaker Recognition
Mar 10, 2022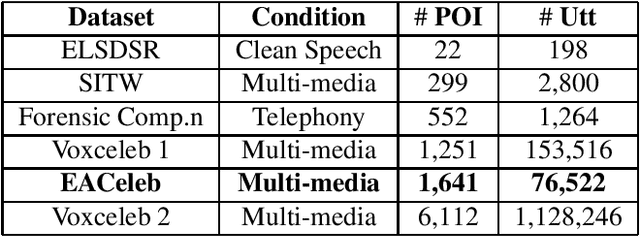



Large datasets are very useful for training speaker recognition systems, and various research groups have constructed several over the years. Voxceleb is a large dataset for speaker recognition that is extracted from Youtube videos. This paper presents an audio-visual method for acquiring audio data from Youtube given the speaker's name as input. The system follows a pipeline similar to that of the Voxceleb data acquisition method. However, our work focuses on fast data acquisition by using face-tracking in subsequent frames once a face has been detected -- this is preferable over face detection for every frame considering its computational cost. We show that applying audio diarization to our data after acquiring it can yield equal error rates comparable to Voxceleb. A secondary set of experiments showed that we could further decrease the error rate by fine-tuning a pre-trained x-vector system with the acquired data. Like Voxceleb, the work here focuses primarily on developing audio for celebrities. However, unlike Voxceleb, our target audio data is from celebrities in East Asian countries. Finally, we set up a speaker verification task to evaluate the accuracy of our acquired data. After diarization and fine-tuning, we achieved an equal error rate of approximately 4\% across our entire dataset.
An Environmental Feature Representation in I-vector Space for Room Verification and Metadata Estimation
Mar 09, 2022
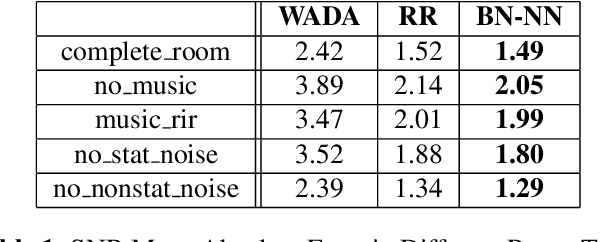


This paper investigates the application of environmental feature representations for room verification tasks and acoustic meta-data estimation. Audio recordings contain both speaker and non-speaker information. We refer to the non-speaker-related information, including channel and other environmental factors, as e-vectors. I-vectors, commonly used in speaker identification, are extracted in the total variability space and capture both speaker and channel-environment information without discrimination. Accordingly, e-vectors can be extracted from i-vectors using methods such as linear discriminant analysis. In this paper, we first demonstrate that e-vectors can be successfully applied to room verification tasks with a low equal error rate. Second, we propose two methods for estimating metadata information -- signal-to-noise (SNR) and reverberation (T60) -- from these e-vectors. When comparing our system to contemporary global SNR estimation methods, in terms of accuracy, we perform favorably even with low dimensional i-vectors. Lastly, we show that room verification tasks can be improved if e-vectors are augmented with the extracted metadata information.