 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Minimal Degree Bias in Generalization on the Unseen for non-Boolean Functions
Jun 10, 2024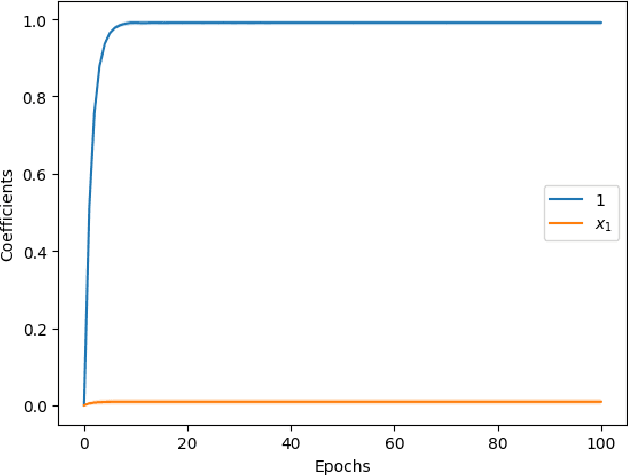



We investigate the out-of-domain generalization of random feature (RF) models and Transformers. We first prove that in the `generalization on the unseen (GOTU)' setting, where training data is fully seen in some part of the domain but testing is made on another part, and for RF models in the small feature regime, the convergence takes place to interpolators of minimal degree as in the Boolean case (Abbe et al., 2023). We then consider the sparse target regime and explain how this regime relates to the small feature regime, but with a different regularization term that can alter the picture in the non-Boolean case. We show two different outcomes for the sparse regime with q-ary data tokens: (1) if the data is embedded with roots of unities, then a min-degree interpolator is learned like in the Boolean case for RF models, (2) if the data is not embedded as such, e.g., simply as integers, then RF models and Transformers may not learn minimal degree interpolators. This shows that the Boolean setting and its roots of unities generalization are special cases where the minimal degree interpolator offers a rare characterization of how learning takes place. For more general integer and real-valued settings, a more nuanced picture remains to be fully characterized.
Multilayer Lookahead: a Nested Version of Lookahead
Oct 27, 2021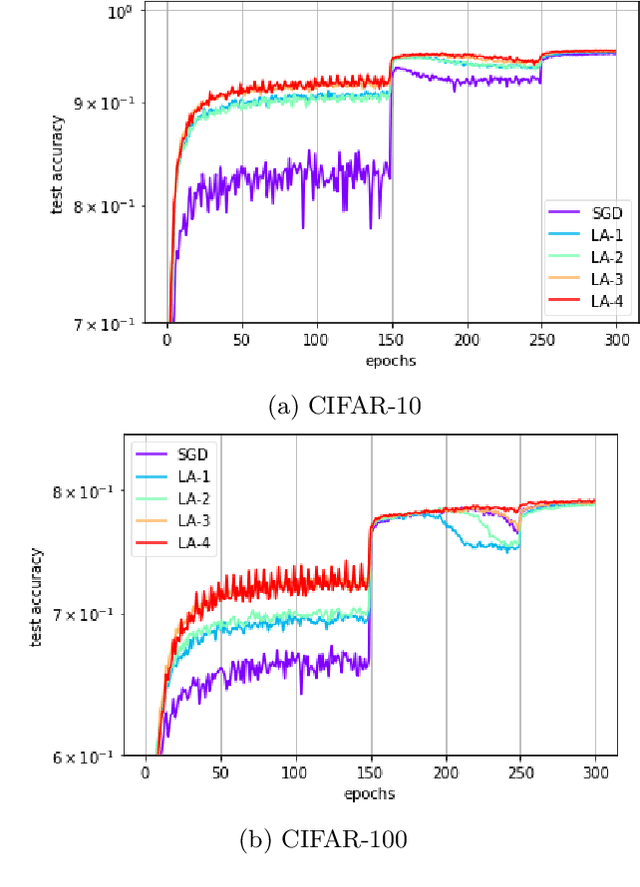


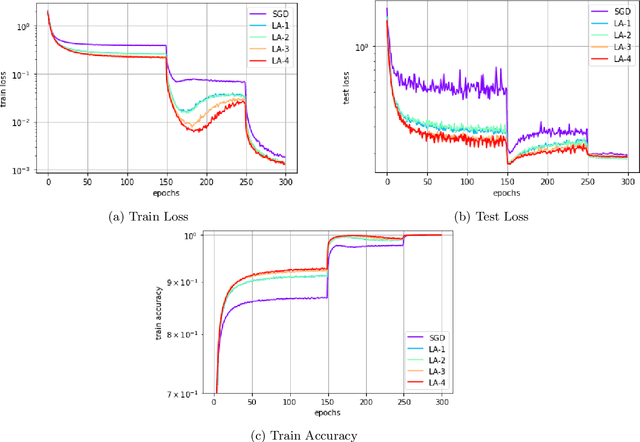
In recent years, SGD and its variants have become the standard tool to train Deep Neural Networks. In this paper, we focus on the recently proposed variant Lookahead, which improves upon SGD in a wide range of applications. Following this success, we study an extension of this algorithm, the \emph{Multilayer Lookahead} optimizer, which recursively wraps Lookahead around itself. We prove the convergence of Multilayer Lookahead with two layers to a stationary point of smooth non-convex functions with $O(\frac{1}{\sqrt{T}})$ rate. We also justify the improved generalization of both Lookahead over SGD, and of Multilayer Lookahead over Lookahead, by showing how they amplify the implicit regularization effect of SGD. We empirically verify our results and show that Multilayer Lookahead outperforms Lookahead on CIFAR-10 and CIFAR-100 classification tasks, and on GANs training on the MNIST dataset.