 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-free reinforcement learning with noisy actions for automated experimental control in optics
May 24, 2024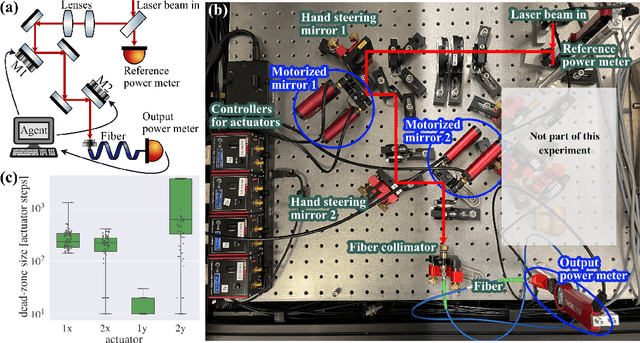



Experimental control involves a lot of manual effort with non-trivial decisions for precise adjustments. Here, we study the automatic experimental alignment for coupling laser light into an optical fiber using reinforcement learning (RL). We face several real-world challenges, such as time-consuming training, partial observability, and noisy actions due to imprecision in the mirror steering motors. We show that we can overcome these challenges: To save time, we use a virtual testbed to tune our environment for dealing with partial observability and use relatively sample-efficient model-free RL algorithms like Soft Actor-Critic (SAC) or Truncated Quantile Critics (TQC). Furthermore, by fully training on the experiment, the agent learns directly to handle the noise present. In our extensive experimentation, we show that we are able to achieve 90% coupling, showcasing the effectiveness of our proposed approaches. We reach this efficiency, which is comparable to that of a human expert, without additional feedback loops despite the motors' inaccuracies. Our result is an example of the readiness of RL for real-world tasks. We consider RL a promising tool for reducing the workload in labs.