 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe BLue Amazon Brain : A Modular Architecture of Services about the Brazilian Maritime Territory
Sep 06, 2022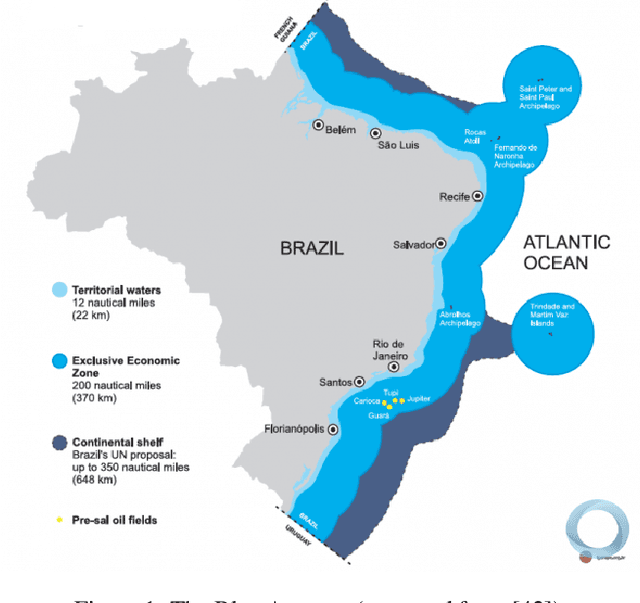
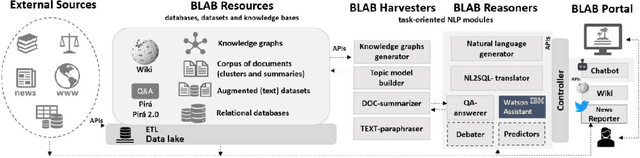
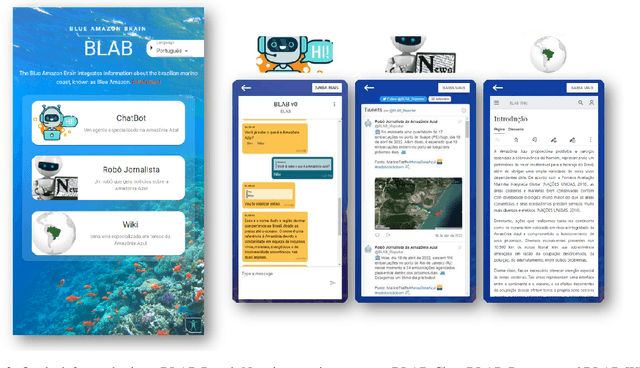
We describe the first steps in the development of an artificial agent focused on the Brazilian maritime territory, a large region within the South Atlantic also known as the Blue Amazon. The "BLue Amazon Brain" (BLAB) integrates a number of services aimed at disseminating information about this region and its importance, functioning as a tool for environmental awareness. The main service provided by BLAB is a conversational facility that deals with complex questions about the Blue Amazon, called BLAB-Chat; its central component is a controller that manages several task-oriented natural language processing modules (e.g., question answering and summarizer systems). These modules have access to an internal data lake as well as to third-party databases. A news reporter (BLAB-Reporter) and a purposely-developed wiki (BLAB-Wiki) are also part of the BLAB service architecture. In this paper, we describe our current version of BLAB's architecture (interface, backend, web services, NLP modules, and resources) and comment on the challenges we have faced so far, such as the lack of training data and the scattered state of domain information. Solving these issues presents a considerable challenge in the development of artificial intelligence for technical domains.
Approximation Complexity of Maximum A Posteriori Inference in Sum-Product Networks
Sep 05, 2017
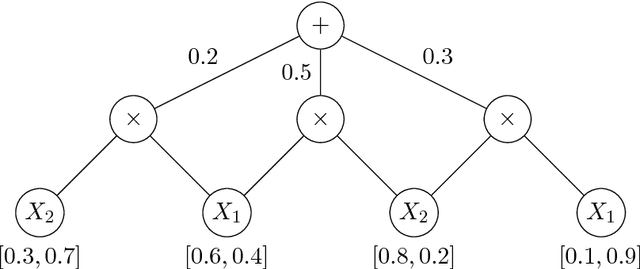

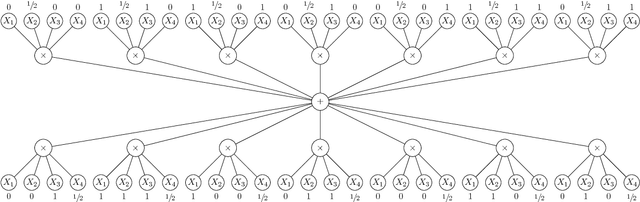
We discuss the computational complexity of approximating maximum a posteriori inference in sum-product networks. We first show NP-hardness in trees of height two by a reduction from maximum independent set; this implies non-approximability within a sublinear factor. We show that this is a tight bound, as we can find an approximation within a linear factor in networks of height two. We then show that, in trees of height three, it is NP-hard to approximate the problem within a factor $2^{f(n)}$ for any sublinear function $f$ of the size of the input $n$. Again, this bound is tight, as we prove that the usual max-product algorithm finds (in any network) approximations within factor $2^{c \cdot n}$ for some constant $c < 1$. Last, we present a simple algorithm, and show that it provably produces solutions at least as good as, and potentially much better than, the max-product algorithm. We empirically analyze the proposed algorithm against max-product using synthetic and realistic networks.
Speeding-up ProbLog's Parameter Learning
Aug 01, 2017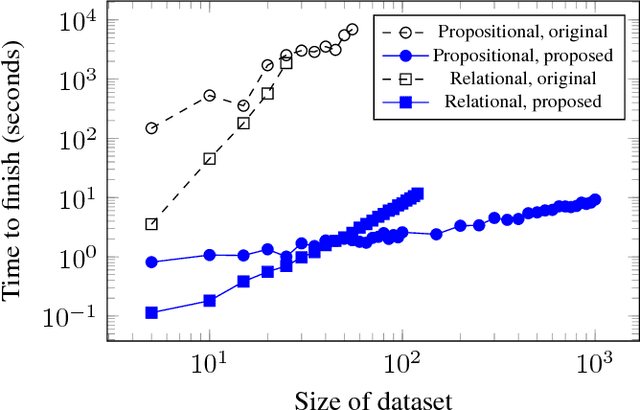
ProbLog is a state-of-art combination of logic programming and probabilities; in particular ProbLog offers parameter learning through a variant of the EM algorithm. However, the resulting learning algorithm is rather slow, even when the data are complete. In this short paper we offer some insights that lead to orders of magnitude improvements in ProbLog's parameter learning speed with complete data.