 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembox: Weaving Topic Continuity into Long-Range Memory for LLM Agents
Jan 07, 2026Human-agent dialogues often exhibit topic continuity-a stable thematic frame that evolves through temporally adjacent exchanges-yet most large language model (LLM) agent memory systems fail to preserve it. Existing designs follow a fragmentation-compensation paradigm: they first break dialogue streams into isolated utterances for storage, then attempt to restore coherence via embedding-based retrieval. This process irreversibly damages narrative and causal flow, while biasing retrieval towards lexical similarity. We introduce membox, a hierarchical memory architecture centered on a Topic Loom that continuously monitors dialogue in a sliding-window fashion, grouping consecutive same-topic turns into coherent "memory boxes" at storage time. Sealed boxes are then linked by a Trace Weaver into long-range event-timeline traces, recovering macro-topic recurrences across discontinuities. Experiments on LoCoMo demonstrate that Membox achieves up to 68% F1 improvement on temporal reasoning tasks, outperforming competitive baselines (e.g., Mem0, A-MEM). Notably, Membox attains these gains while using only a fraction of the context tokens required by existing methods, highlighting a superior balance between efficiency and effectiveness. By explicitly modeling topic continuity, Membox offers a cognitively motivated mechanism for enhancing both coherence and efficiency in LLM agents.
Clue-Guided Path Exploration: An Efficient Knowledge Base Question-Answering Framework with Low Computational Resource Consumption
Jan 24, 2024In recent times, large language models (LLMs) have showcased remarkable capabilities. However, updating their knowledge poses challenges, potentially leading to inaccuracies when confronted with unfamiliar queries. While integrating knowledge graphs with LLMs has been explored, existing approaches treat LLMs as primary decision-makers, imposing high demands on their capabilities. This is particularly unsuitable for LLMs with lower computational costs and relatively poorer performance. In this paper, we introduce a Clue-Guided Path Exploration framework (CGPE) that efficiently merges a knowledge base with an LLM, placing less stringent requirements on the model's capabilities. Inspired by the method humans use to manually retrieve knowledge, CGPE employs information from the question as clues to systematically explore the required knowledge path within the knowledge base. Experiments on open-source datasets reveal that CGPE outperforms previous methods and is highly applicable to LLMs with fewer parameters. In some instances, even ChatGLM3, with its 6 billion parameters, can rival the performance of GPT-4. Furthermore, the results indicate a minimal invocation frequency of CGPE on LLMs, suggesting reduced computational overhead. For organizations and individuals facing constraints in computational resources, our research offers significant practical value.
An unsupervised extractive summarization method based on multi-round computation
Dec 15, 2021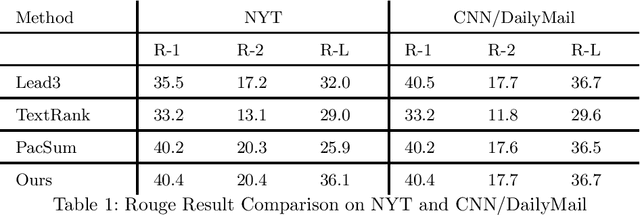
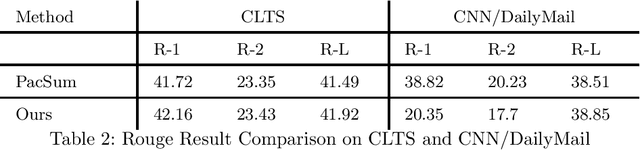
Text summarization methods have attracted much attention all the time. In recent years, deep learning has been applied to text summarization, and it turned out to be pretty effective. However, most of the current text summarization methods based on deep learning need large-scale datasets, which is difficult to achieve in practical applications. In this paper, an unsupervised extractive text summarization method based on multi-round calculation is proposed. Based on the directed graph algorithm, we change the traditional method of calculating the sentence ranking at one time to multi-round calculation, and the summary sentences are dynamically optimized after each round of calculation to better match the characteristics of the text. In this paper, experiments are carried out on four data sets, each separately containing Chinese, English, long and short texts. The experiment results show that our method has better performance than both baseline methods and other unsupervised methods and is robust on different datasets.