 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeg-HGNN: Unsupervised and Light-Weight Image Segmentation with Hyperbolic Graph Neural Networks
Sep 10, 2024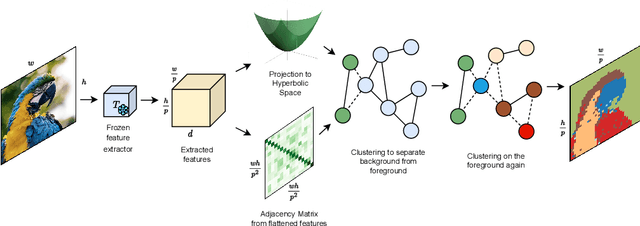
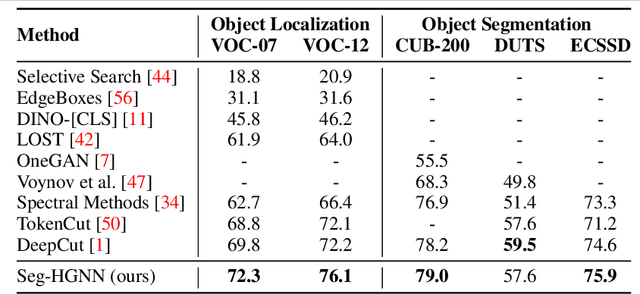

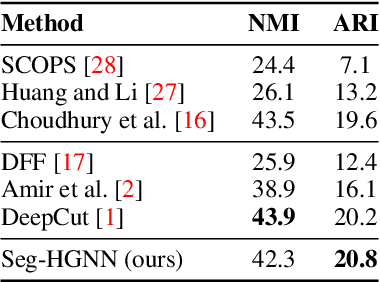
Image analysis in the euclidean space through linear hyperspaces is well studied. However, in the quest for more effective image representations, we turn to hyperbolic manifolds. They provide a compelling alternative to capture complex hierarchical relationships in images with remarkably small dimensionality. To demonstrate hyperbolic embeddings' competence, we introduce a light-weight hyperbolic graph neural network for image segmentation, encompassing patch-level features in a very small embedding size. Our solution, Seg-HGNN, surpasses the current best unsupervised method by 2.5\%, 4\% on VOC-07, VOC-12 for localization, and by 0.8\%, 1.3\% on CUB-200, ECSSD for segmentation, respectively. With less than 7.5k trainable parameters, Seg-HGNN delivers effective and fast ($\approx 2$ images/second) results on very standard GPUs like the GTX1650. This empirical evaluation presents compelling evidence of the efficacy and potential of hyperbolic representations for vision tasks.
KAM-CoT: Knowledge Augmented Multimodal Chain-of-Thoughts Reasoning
Jan 23, 2024



Large Language Models (LLMs) have demonstrated impressive performance in natural language processing tasks by leveraging chain of thought (CoT) that enables step-by-step thinking. Extending LLMs with multimodal capabilities is the recent interest, but incurs computational cost and requires substantial hardware resources. To address these challenges, we propose KAM-CoT a framework that integrates CoT reasoning, Knowledge Graphs (KGs), and multiple modalities for a comprehensive understanding of multimodal tasks. KAM-CoT adopts a two-stage training process with KG grounding to generate effective rationales and answers. By incorporating external knowledge from KGs during reasoning, the model gains a deeper contextual understanding reducing hallucinations and enhancing the quality of answers. This knowledge-augmented CoT reasoning empowers the model to handle questions requiring external context, providing more informed answers. Experimental findings show KAM-CoT outperforms the state-of-the-art methods. On the ScienceQA dataset, we achieve an average accuracy of 93.87%, surpassing GPT-3.5 (75.17%) by 18% and GPT-4 (83.99%) by 10%. Remarkably, KAM-CoT achieves these results with only 280M trainable parameters at a time, demonstrating its cost-efficiency and effectiveness.