 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Contrasting All You Need? Contrastive Learning for the Detection and Attribution of AI-generated Text
Jul 12, 2024The significant progress in the development of Large Language Models has contributed to blurring the distinction between human and AI-generated text. The increasing pervasiveness of AI-generated text and the difficulty in detecting it poses new challenges for our society. In this paper, we tackle the problem of detecting and attributing AI-generated text by proposing WhosAI, a triplet-network contrastive learning framework designed to predict whether a given input text has been generated by humans or AI and to unveil the authorship of the text. Unlike most existing approaches, our proposed framework is conceived to learn semantic similarity representations from multiple generators at once, thus equally handling both detection and attribution tasks. Furthermore, WhosAI is model-agnostic and scalable to the release of new AI text-generation models by incorporating their generated instances into the embedding space learned by our framework. Experimental results on the TuringBench benchmark of 200K news articles show that our proposed framework achieves outstanding results in both the Turing Test and Authorship Attribution tasks, outperforming all the methods listed in the TuringBench benchmark leaderboards.
Open Models, Closed Minds? On Agents Capabilities in Mimicking Human Personalities through Open Large Language Models
Jan 13, 2024
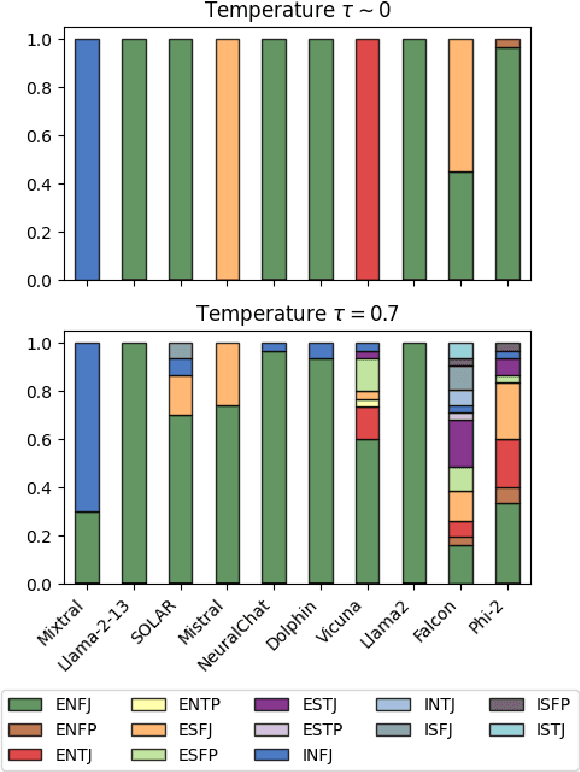

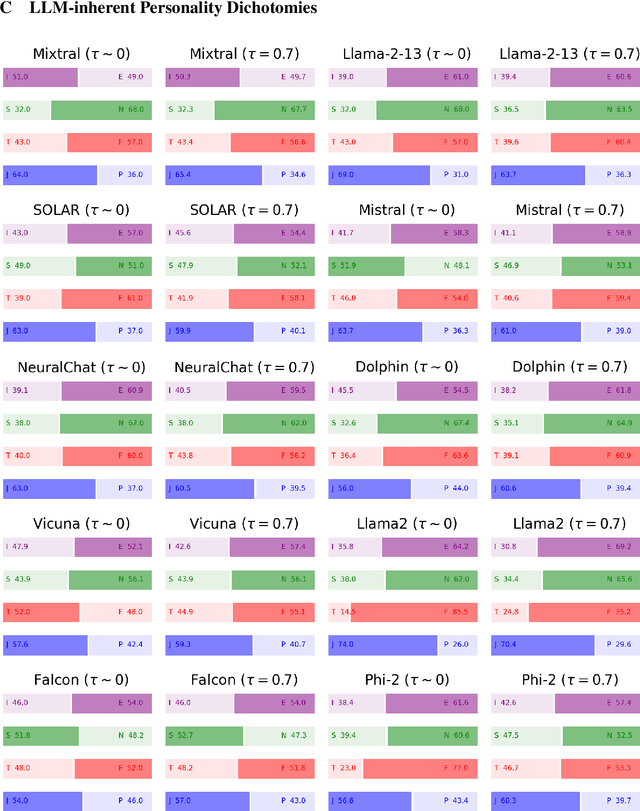
The emergence of unveiling human-like behaviors in Large Language Models (LLMs) has led to a closer connection between NLP and human psychology, leading to a proliferation of computational agents. Scholars have been studying the inherent personalities displayed by LLM agents and attempting to incorporate human traits and behaviors into them. However, these efforts have primarily focused on commercially-licensed LLMs, neglecting the widespread use and notable advancements seen in Open LLMs. This work aims to address this gap by conducting a comprehensive examination of the ability of agents to emulate human personalities using Open LLMs. To achieve this, we generate a set of ten LLM Agents based on the most representative Open models and subject them to a series of assessments concerning the Myers-Briggs Type Indicator (MBTI) test. Our approach involves evaluating the intrinsic personality traits of Open LLM agents and determining the extent to which these agents can mimic human personalities when conditioned by specific personalities and roles. Our findings unveil that: $(i)$ each Open LLM agent showcases distinct human personalities; $(ii)$ personality-conditioned prompting produces varying effects on the agents, with only few successfully mirroring the imposed personality, while most of them being ``closed-minded'' (i.e., they retain their intrinsic traits); $(iii)$ combining role and personality conditioning can enhance the agents' ability to mimic human personalities; and $(iv)$ personalities typically associated with the role of teacher tend to be emulated with greater accuracy. Our work represents a step up in understanding the dense relationship between NLP and human psychology through the lens of Open LLMs.
Visually Wired NFTs: Exploring the Role of Inspiration in Non-Fungible Tokens
Apr 16, 2023The fervor for Non-Fungible Tokens (NFTs) attracted countless creators, leading to a Big Bang of digital assets driven by latent or explicit forms of inspiration, as in many creative processes. This work exploits Vision Transformers and graph-based modeling to delve into visual inspiration phenomena between NFTs over the years. Our goals include unveiling the main structural traits that shape visual inspiration networks, exploring the interrelation between visual inspiration and asset performances, investigating crypto influence on inspiration processes, and explaining the inspiration relationships among NFTs. Our findings unveil how the pervasiveness of inspiration led to a temporary saturation of the visual feature space, the impact of the dichotomy between inspiring and inspired NFTs on their financial performance, and an intrinsic self-regulatory mechanism between markets and inspiration waves. Our work can serve as a starting point for gaining a broader view of the evolution of Web3.
Show me your NFT and I tell you how it will perform: Multimodal representation learning for NFT selling price prediction
Feb 06, 2023Non-Fungible Tokens (NFTs) represent deeds of ownership, based on blockchain technologies and smart contracts, of unique crypto assets on digital art forms (e.g., artworks or collectibles). In the spotlight after skyrocketing in 2021, NFTs have attracted the attention of crypto enthusiasts and investors intent on placing promising investments in this profitable market. However, the NFT financial performance prediction has not been widely explored to date. In this work, we address the above problem based on the hypothesis that NFT images and their textual descriptions are essential proxies to predict the NFT selling prices. To this purpose, we propose MERLIN, a novel multimodal deep learning framework designed to train Transformer-based language and visual models, along with graph neural network models, on collections of NFTs' images and texts. A key aspect in MERLIN is its independence on financial features, as it exploits only the primary data a user interested in NFT trading would like to deal with, i.e., NFT images and textual descriptions. By learning dense representations of such data, a price-category classification task is performed by MERLIN models, which can also be tuned according to user preferences in the inference phase to mimic different risk-return investment profiles. Experimental evaluation on a publicly available dataset has shown that MERLIN models achieve significant performances according to several financial assessment criteria, fostering profitable investments, and also beating baseline machine-learning classifiers based on financial features.