 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCISOL: An Open and Extensible Dataset for Table Structure Recognition in the Construction Industry
Jan 26, 2025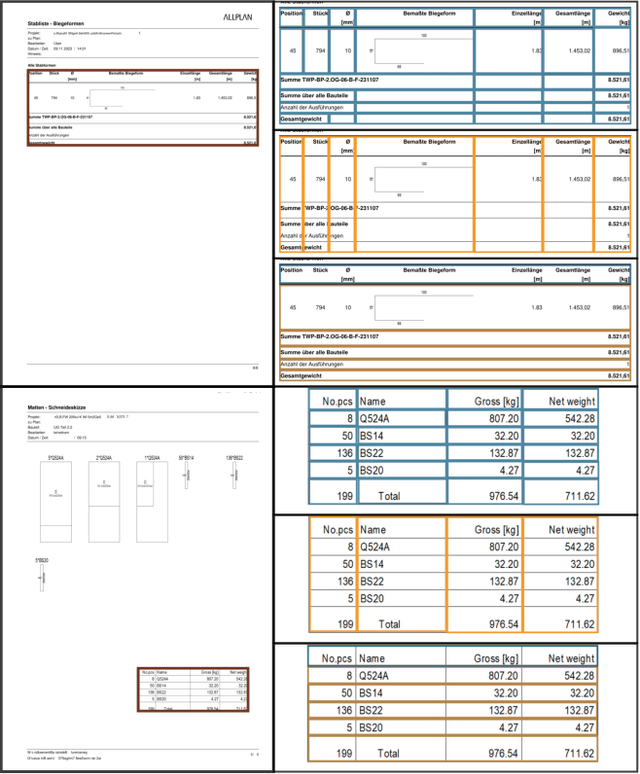
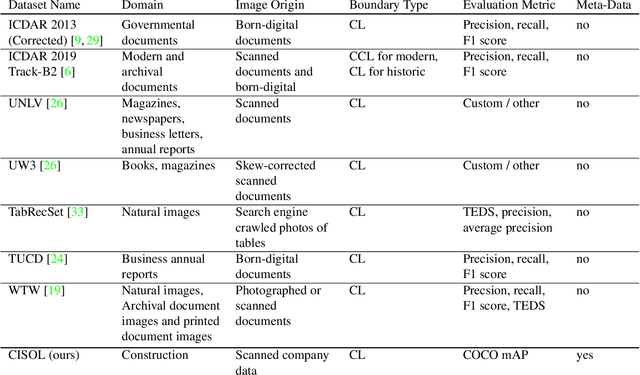
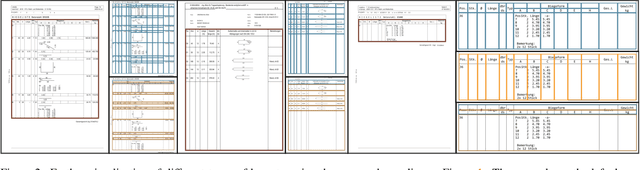
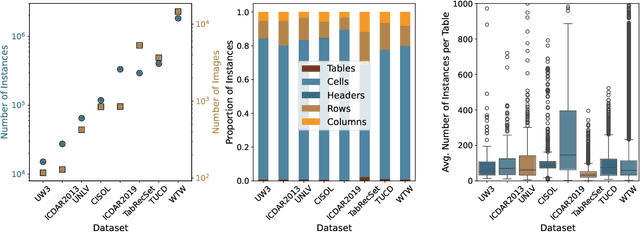
Reproducibility and replicability are critical pillars of empirical research, particularly in machine learning, where they depend not only on the availability of models, but also on the datasets used to train and evaluate those models. In this paper, we introduce the Construction Industry Steel Ordering List (CISOL) dataset, which was developed with a focus on transparency to ensure reproducibility, replicability, and extensibility. CISOL provides a valuable new research resource and highlights the importance of having diverse datasets, even in niche application domains such as table extraction in civil engineering. CISOL is unique in that it contains real-world civil engineering documents from industry, making it a distinctive contribution to the field. The dataset contains more than 120,000 annotated instances in over 800 document images, positioning it as a medium-sized dataset that provides a robust foundation for Table Structure Recognition (TSR) and Table Detection (TD) tasks. Benchmarking results show that CISOL achieves 67.22 mAP@0.5:0.95:0.05 using the YOLOv8 model, outperforming the TSR-specific TATR model. This highlights the effectiveness of CISOL as a benchmark for advancing TSR, especially in specialized domains.
Label Convergence: Defining an Upper Performance Bound in Object Recognition through Contradictory Annotations
Sep 14, 2024Annotation errors are a challenge not only during training of machine learning models, but also during their evaluation. Label variations and inaccuracies in datasets often manifest as contradictory examples that deviate from established labeling conventions. Such inconsistencies, when significant, prevent models from achieving optimal performance on metrics such as mean Average Precision (mAP). We introduce the notion of "label convergence" to describe the highest achievable performance under the constraint of contradictory test annotations, essentially defining an upper bound on model accuracy. Recognizing that noise is an inherent characteristic of all data, our study analyzes five real-world datasets, including the LVIS dataset, to investigate the phenomenon of label convergence. We approximate that label convergence is between 62.63-67.52 mAP@[0.5:0.95:0.05] for LVIS with 95% confidence, attributing these bounds to the presence of real annotation errors. With current state-of-the-art (SOTA) models at the upper end of the label convergence interval for the well-studied LVIS dataset, we conclude that model capacity is sufficient to solve current object detection problems. Therefore, future efforts should focus on three key aspects: (1) updating the problem specification and adjusting evaluation practices to account for unavoidable label noise, (2) creating cleaner data, especially test data, and (3) including multi-annotated data to investigate annotation variation and make these issues visible from the outset.
Drawing the Same Bounding Box Twice? Coping Noisy Annotations in Object Detection with Repeated Labels
Sep 18, 2023



The reliability of supervised machine learning systems depends on the accuracy and availability of ground truth labels. However, the process of human annotation, being prone to error, introduces the potential for noisy labels, which can impede the practicality of these systems. While training with noisy labels is a significant consideration, the reliability of test data is also crucial to ascertain the dependability of the results. A common approach to addressing this issue is repeated labeling, where multiple annotators label the same example, and their labels are combined to provide a better estimate of the true label. In this paper, we propose a novel localization algorithm that adapts well-established ground truth estimation methods for object detection and instance segmentation tasks. The key innovation of our method lies in its ability to transform combined localization and classification tasks into classification-only problems, thus enabling the application of techniques such as Expectation-Maximization (EM) or Majority Voting (MJV). Although our main focus is the aggregation of unique ground truth for test data, our algorithm also shows superior performance during training on the TexBiG dataset, surpassing both noisy label training and label aggregation using Weighted Boxes Fusion (WBF). Our experiments indicate that the benefits of repeated labels emerge under specific dataset and annotation configurations. The key factors appear to be (1) dataset complexity, the (2) annotator consistency, and (3) the given annotation budget constraints.