 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Identifiability of Interventional Stochastic Differential Equations
May 21, 2025We study identifiability of stochastic differential equation (SDE) models under multiple interventions. Our results give the first provable bounds for unique recovery of SDE parameters given samples from their stationary distributions. We give tight bounds on the number of necessary interventions for linear SDEs, and upper bounds for nonlinear SDEs in the small noise regime. We experimentally validate the recovery of true parameters in synthetic data, and motivated by our theoretical results, demonstrate the advantage of parameterizations with learnable activation functions.
An Infinite Latent Attribute Model for Network Data
Jun 27, 2012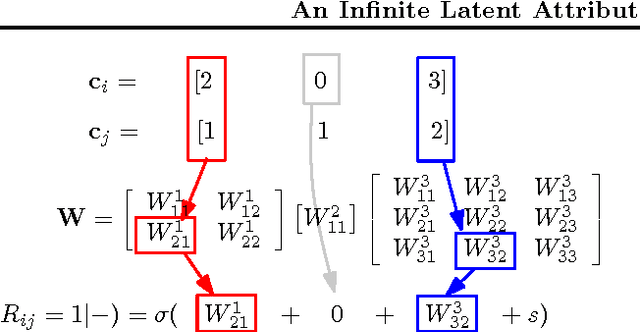



Latent variable models for network data extract a summary of the relational structure underlying an observed network. The simplest possible models subdivide nodes of the network into clusters; the probability of a link between any two nodes then depends only on their cluster assignment. Currently available models can be classified by whether clusters are disjoint or are allowed to overlap. These models can explain a "flat" clustering structure. Hierarchical Bayesian models provide a natural approach to capture more complex dependencies. We propose a model in which objects are characterised by a latent feature vector. Each feature is itself partitioned into disjoint groups (subclusters), corresponding to a second layer of hierarchy. In experimental comparisons, the model achieves significantly improved predictive performance on social and biological link prediction tasks. The results indicate that models with a single layer hierarchy over-simplify real networks.
Nonparametric Bayesian sparse factor models with application to gene expression modeling
Jul 28, 2011



A nonparametric Bayesian extension of Factor Analysis (FA) is proposed where observed data $\mathbf{Y}$ is modeled as a linear superposition, $\mathbf{G}$, of a potentially infinite number of hidden factors, $\mathbf{X}$. The Indian Buffet Process (IBP) is used as a prior on $\mathbf{G}$ to incorporate sparsity and to allow the number of latent features to be inferred. The model's utility for modeling gene expression data is investigated using randomly generated data sets based on a known sparse connectivity matrix for E. Coli, and on three biological data sets of increasing complexity.
* Published in at http://dx.doi.org/10.1214/10-AOAS435 the Annals of Applied Statistics (http://www.imstat.org/aoas/) by the Institute of Mathematical Statistics (http://www.imstat.org)