 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian score calibration for approximate models
Nov 11, 2022Scientists continue to develop increasingly complex mechanistic models to reflect their knowledge more realistically. Statistical inference using these models can be highly challenging, since the corresponding likelihood function is often intractable, and model simulation may be computationally burdensome or infeasible. Fortunately, in many of these situations, it is possible to adopt a surrogate model or approximate likelihood function. It may be convenient to base Bayesian inference directly on the surrogate, but this can result in bias and poor uncertainty quantification. In this paper we propose a new method for adjusting approximate posterior samples to reduce bias and produce more accurate uncertainty quantification. We do this by optimising a transform of the approximate posterior that minimises a scoring rule. Our approach requires only a (fixed) small number of complex model simulations and is numerically stable. We demonstrate good performance of the new method on several examples of increasing complexity.
Improving the Accuracy of Marginal Approximations in Likelihood-Free Inference via Localisation
Jul 14, 2022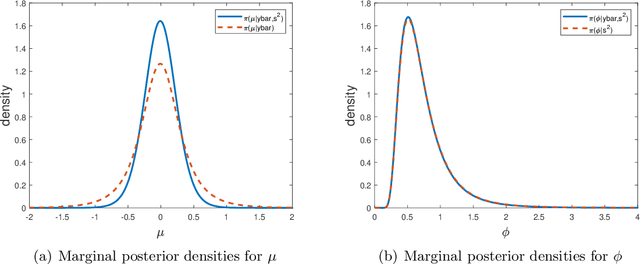

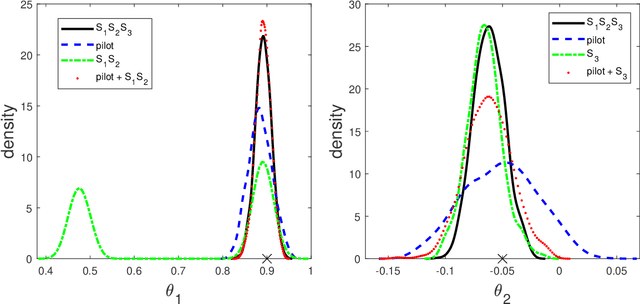
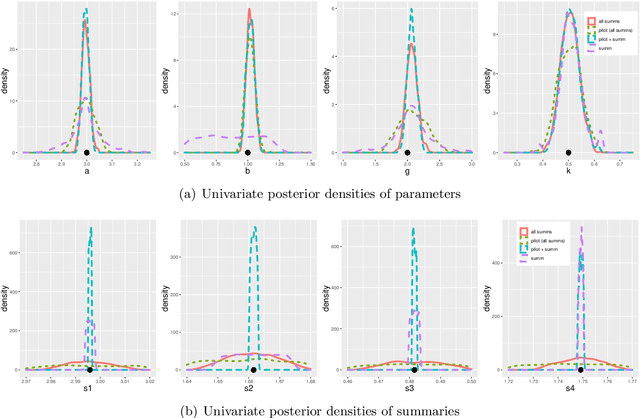
Likelihood-free methods are an essential tool for performing inference for implicit models which can be simulated from, but for which the corresponding likelihood is intractable. However, common likelihood-free methods do not scale well to a large number of model parameters. A promising approach to high-dimensional likelihood-free inference involves estimating low-dimensional marginal posteriors by conditioning only on summary statistics believed to be informative for the low-dimensional component, and then combining the low-dimensional approximations in some way. In this paper, we demonstrate that such low-dimensional approximations can be surprisingly poor in practice for seemingly intuitive summary statistic choices. We describe an idealized low-dimensional summary statistic that is, in principle, suitable for marginal estimation. However, a direct approximation of the idealized choice is difficult in practice. We thus suggest an alternative approach to marginal estimation which is easier to implement and automate. Given an initial choice of low-dimensional summary statistic that might only be informative about a marginal posterior location, the new method improves performance by first crudely localising the posterior approximation using all the summary statistics to ensure global identifiability, followed by a second step that hones in on an accurate low-dimensional approximation using the low-dimensional summary statistic. We show that the posterior this approach targets can be represented as a logarithmic pool of posterior distributions based on the low-dimensional and full summary statistics, respectively. The good performance of our method is illustrated in several examples.